우아한 프리코스 1주차
우아한 프리코스 1주차

프리코스를 시작하면서…
문제 해결을 위한 첫 번째 접근
우테코의 요구조건에 맞게 우선 Readme에 구현해야할 기능별 목표를 정하고 문제풀이를 진행했다

우테코에서는 기능 구현을 하기 전 명확한 기능 설계를 하는 것을 요구했다. 개인적으로 프로젝트에서 기능 명세를 작성하는 것과 크게 다르지 않다고 느꼈는데, 아마 프리코스도 기능 명세를 작성하고 이에 맞게 코드를 짜는 경험을 시켜주고 싶었던 것 같다.
프리코스의 의도
우테코에서 제공한 Console 클래스를 사용하면서 자연스럽게 싱글톤 패턴을 학습하게 되었다. 처음에는 Console 객체를 만들기 위해 Console console = new Console(); 과 같은 방식으로 생성하려 했지만, IDE에서 에러가 발생했다. “왜 객체 생성이 안 될까?”라는 의문이 생겨 Console 클래스 내부를 확인해보니, 생성자가 private으로 설정되어 있었다.
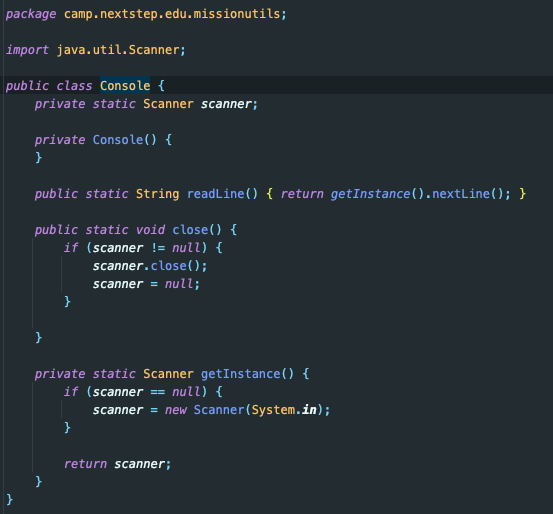
이는 단순한 실수가 아니라 우테코가 의도적으로 싱글톤 패턴을 적용한 것임을 알 수 있었다. 싱글톤 패턴은 프로그램에서 하나의 객체만 생성해 사용하도록 제한하는 디자인 패턴이다. 즉, Console 클래스는 하나의 인스턴스만 사용하게 설계되어 있어, 입력과 출력을 처리하는 과정에서 여러 객체를 만들 필요가 없다는 장점이 있었다.
이 과정에서 싱글톤 패턴의 이점도 자연스럽게 체득할 수 있었다. 하나의 인스턴스만 사용함으로써 시스템 자원을 절약할 수 있고, 프로그램 전반에서 일관된 동작을 보장할 수 있다. 특히 내가 작성한 문자열 계산기처럼 입력과 출력이 반복적으로 사용되는 프로그램에서 싱글톤 패턴은 매우 유용하다는 것을 실감하게 되었다.
우테코가 의도적으로 이러한 구조를 제공한 이유도 명확했다. 나처럼 처음에는 직접 객체를 생성하려 하다가 에러를 마주한 사람은 왜 그런지 궁금해할 것이고, 이를 통해 싱글톤 패턴의 존재와 그 의미를 자연스럽게 학습할 수 있게 된다는 점이다. 그래서 앞으로도 프리코스 과제를 하면서 우테코의 설계 의도를 파악하고 이에 알맞게 코드를 짜야겠다고 생각하게 되었다.
커스텀 구분자 처리 과정에서의 깨달음
최초에 문제 풀이를 하면서도 커스텀 구분자를 처리하는 로직을 작성하면서 어려움을 겪었다.
처음에는 간단하게 split() 메서드를 사용하여 \n을 기준으로 문자열을 나누려고 했다. 그래서 다음과 같이 코드를 작성했다
1
text.split("\n");
하지만 예상과 달리 이 코드는 제대로 작동하지 않았다. 왜냐하면, Java에서 역슬래시는 특수한 의미를 가지고 있기 때문이다. \n, \t 같은걸 사용해 본 사람이라면 역슬래시가 특별하게 사용된다는 것을 체감해봤을 것이다. 이렇게 사용되는 문자를 이스케이프 문자라고 하는데, Java에서 역슬래시가 문자열 내에서 이스케이프 문자로 사용되기 때문에 split(“\n”) 표현으로는 정상작동하지 않는 것이다.
결과적으로 \n 문자열을 기준으로 텍스트를 분할할 때는 다음과 같은 표현식을 사용해야 했다
1
text.split("\\\\n");
원리를 알고 실행했던 것이 아니라 \를 그냥 계속 추가해보면서 테스트했다. 결과적으로 \가 3개 더 추가된 형태였는데, \n을 표현하기 위해 \가 3개나 더 추가되니 혼란스러울 수 밖에 없었다.
그래서 그 원리를 알아보았다.
- \n (문자 리터럴)
- 이스케이프 문자인 \n은 줄바꿈으로 해석됩니다.
- 예시: “Hello\nWorld” → “Hello” (줄바꿈) “World”
- 정규 표현식: \n은 정규 표현식에서도 줄바꿈 문자로 해석됩니다.
- 예시: Pattern.compile(“\n”) → 줄바꿈을 찾는 정규식
- \n (문자 리터럴과 정규 표현식의 처리)
- Java에서는 역슬래시()가 이스케이프 문자로 사용되기 때문에, “\n”은 문자열 내에서 단일 역슬래시 + n으로 해석됩니다.
- 예시: “\n” → “\n” (이때 문자열에서는 단순히 문자열 “n” 앞에 역슬래시가 붙은 형태로 출력되지 않음)
- 정규 표현식: “\n”을 정규식에서 사용하면, 이는 실제로 줄바꿈 문자로 해석됩니다.
- 예시: Pattern.compile(“\n”) → 정규 표현식에서 \는 역슬래시 자체를 나타내며, 결국 줄바꿈 문자인 \n을 찾습니다.
- \\n (문자 리터럴과 정규 표현식에서의 문제)
- 역슬래시가 3번 사용되었을 때는, 앞의 두 개의 역슬래시는 하나의 역슬래시로 해석되고, 그 다음에 줄바꿈 문자가 온 것으로 처리됩니다.
- 예시: “\\n” → “\(줄바꿈)” (이 구문은 \ 다음에 줄바꿈이 되어 에러가 발생할 가능성이 큽니다)
- 정규 표현식: “\\n”은 정규식에서 사용하면 에러가 발생할 수 있습니다. Java는 \\를 이스케이프 처리하므로, \\n은 잘못된 형식으로 해석됩니다.
- 예시: Pattern.compile(“\\n”) → 에러
- \\n(정확한 처리)
- 여기서 앞의 네 개의 역슬래시 중 두 개는 단일 역슬래시로 해석되고, 그 다음 두 개는 다시 역슬래시 + n으로 해석됩니다.
- 예시: “\\n” → “\\n” (역슬래시 문자 그대로와 문자 n이 나타납니다)
- 정규 표현식: “\\n”을 정규 표현식에서 사용하면, 이는 \\n으로 해석되어 줄바꿈 문자를 의미하게 됩니다.
- 예시: Pattern.compile(“\\n”) → 줄바꿈 문자를 찾는 정규 표현식 (\n을 찾습니다)
Pattern과 Matcher 사용
그 다음으로는 Pattern과 Matcher를 사용해 커스텀 구분자를 처리하는 방법을 배웠다. Pattern.compile()로 정규 표현식을 컴파일하고, Matcher를 통해 입력 문자열에서 커스텀 구분자를 추출했다. 정규식을 통해 사용자로부터 제공된 구분자를 인식하고 나면, 그 구분자를 이용해 문자열을 나눌 수 있었다.
1
2
3
4
5
6
Matcher matcher = Pattern.compile("//(.)\\\\n(.*)").matcher(input);
if (matcher.find()) {
String customDelimiter = matcher.group(1);
String numbers = matcher.group(2);
return numbers.split(DEFAULT_DELIMITER + "|" + Pattern.quote(customDelimiter));
}
이 과정에서 Pattern과 Matcher의 강력한 문자열 매칭 기능을 체험할 수 있었다. 처음에는 복잡해 보였지만, 이를 통해 Java의 정규 표현식 처리 방식에 대해 더 깊이 이해하게 되었다. 특히 group() 메서드를 사용해 특정 부분을 추출하고, 이를 사용해 동적으로 구분자를 처리하는 로직을 구현한 것이 신기하고 재미있었다.
이 경험을 통해, 앞으로 복잡한 문자열 처리나 규칙을 동적으로 적용해야 하는 상황에서도 자신감을 가지고 접근할 수 있을 것 같다. Java에서 문자열을 다루는 다양한 방법을 직접 경험하면서, 작은 실수에서 큰 교훈을 얻은 순간이었다.
개선된 코드 - 더 나은 구조와 책임 분리
처음 내가 작성했던 Calculator 클래스는 모든 로직을 한곳에 몰아넣는 형태였지만, 지금은 각 역할을 담당하는 클래스로 분리되었다. 이는 단일 책임 원칙(SRP) 을 적용한 결과로, 각 클래스가 명확한 역할을 맡게 되어 유지보수성과 가독성이 크게 향상되었다.
초기의 Calculator 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
package calculator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Calculator {
private static final String DEFAULT_DELIMITER = ",|:";
public static int add(String text) {
if (text == null || text.isEmpty()) {
return 0;
}
return sum(split(text));
}
private static String[] split(String text) {
Matcher matcher = Pattern.compile("//(.)\\\\n(.*)").matcher(text);
if (matcher.find()) {
String customDelimiter = matcher.group(1);
// ... 생략
}
// ... 생략
}
private static int sum(String[] values) {
int sum = 0;
for (String value : values) {
sum += Integer.parseInt(value);
int number = toPositive(value);
sum += number;
}
return sum;
}
private static int toPositive(String value) {
try {
int number = Integer.parseInt(value);
if (number < 0) {
throw new IllegalArgumentException("음수는 허용되지 않습니다: " + value);
}
return number;
} catch (NumberFormatException e) {
throw new IllegalArgumentException("숫자가 아닌 값이 포함되어 있습니다: " + value);
}
}
}
이 코드는 모든 기능을 Calculator 클래스에 집중시키고 있다. 입력을 처리하고, 구분자를 파싱하며, 숫자 유효성 검사까지 모두 한 클래스에서 담당하고 있기 때문에 유지보수와 확장이 어려운 구조였다.
개선된 구조
리팩토링된 코드에서는 입력 파싱, 유효성 검사, 계산의 역할을 각각의 클래스로 분리했다. 이를 통해 각 클래스가 하나의 역할만을 담당하게 되어 단일 책임 원칙(SRP)이 잘 적용되었다.
- InputParser: 입력을 파싱하고 커스텀 구분자를 처리하는 역할.
- Validator: 입력된 값의 유효성을 검사하는 역할.
- SumCalculator: 파싱된 숫자를 받아 계산하는 역할.
개선된 InputParser 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public class InputParser {
private static final String DEFAULT_DELIMITER = ",|:";
private final Validator validator;
public InputParser() {
this.validator = new Validator();
}
public List<Integer> parse(String input) {
Matcher matcher = Pattern.compile("//(.)\\\\n(.*)").matcher(input);
if (matcher.find()) {
String customDelimiter = matcher.group(1);
validator.validateCustomDelimiter(DEFAULT_DELIMITER, customDelimiter);
String numbers = matcher.group(2);
return toPositiveIntegerList(numbers.split(DEFAULT_DELIMITER + "|" + Pattern.quote(customDelimiter)));
}
return toPositiveIntegerList(input.split(DEFAULT_DELIMITER));
}
private List<Integer> toPositiveIntegerList(String[] tokens) {
List<Integer> numbers = new ArrayList<>();
for (String token : tokens) {
int number = validator.toPositiveInteger(token);
numbers.add(number);
}
return numbers;
}
}
개선된 Validator 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public class Validator {
public int toPositiveInteger(String value) {
try {
int number = Integer.parseInt(value);
if (number < 0) {
ExceptionHandler.throwIllegalArgException(NEGATIVE_NUMBER, value);
}
return number;
} catch (NumberFormatException e) {
ExceptionHandler.throwIllegalArgException(INVALID_NUMBER, value);
return 0; // 도달하지 않음
}
}
public void validateCustomDelimiter(String default_delimiter, String custom_delimiter) {
if (custom_delimiter.length() != 1) {
ExceptionHandler.throwIllegalArgException(INVALID_LENGTH);
}
if (Character.isDigit(custom_delimiter.charAt(0))) {
ExceptionHandler.throwIllegalArgException(DIGIT_NOT_ALLOWED);
}
if (default_delimiter.contains(custom_delimiter)) {
ExceptionHandler.throwIllegalArgException(DUPLICATE_DELIMITER);
}
}
}
개선된 SumCalculator 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class SumCalculator implements Calculator {
@Override
public int add(List<Integer> numbers) {
int sum = 0;
for (int number : numbers) {
sum = safeAdd(sum, number);
}
return sum;
}
private static int safeAdd(int a, int b) {
try {
return Math.addExact(a, b);
} catch (ArithmeticException e) {
ExceptionHandler.throwIllegalArgException(OUT_OF_RANGE);
return 0; // 도달하지 않음
}
}
}
예외 처리와 코드 안정성
이전 코드에서는 예외 처리가 간단하게 되어 있었지만, 이제는 Validator 클래스를 통해 명확하고 구체적인 예외 처리가 가능해졌다. 예외 메시지는 ErrorMessage enum을 통해 관리하며, 이를 통해 유지보수성이 향상되었다.
1
2
3
4
5
6
7
8
public enum ErrorMessage {
NEGATIVE_NUMBER("음수는 허용되지 않습니다: %s"),
INVALID_NUMBER("숫자가 아닌 값이 포함되어 있습니다: %s"),
INVALID_LENGTH("커스텀 구분자의 길이는 1이어야 합니다."),
DIGIT_NOT_ALLOWED("커스텀 구분자는 숫자가 될 수 없습니다."),
DUPLICATE_DELIMITER("커스텀 구분자는 기본 구분자와 중복될 수 없습니다."),
OUT_OF_RANGE("계산 결과가 표현 범위를 초과했습니다.");
}
이처럼 명확한 예외 처리를 통해 프로그램의 안정성과 신뢰성을 높일 수 있었다.
마무리
이번 프로젝트에서 처음에는 단순히 기능 구현에만 초점을 맞췄지만, 시간이 지나면서 구조적인 개선이 필요하다는 것을 깨닫고 리팩토링을 진행했다. 각 클래스가 자신의 책임을 명확하게 나누어 맡고, 유지보수성이 높은 코드를 작성하게 되었다. 이를 통해 내가 작성한 코드의 품질이 크게 향상되었고, 앞으로도 이러한 리팩토링과 개선의 과정이 필수적임을 알게 되었다.