Redis 이 정도는 알고 쓰자
Redis 이 정도는 알고 쓰자

많은 사람들이 세션, 캐싱 스토리지나 메시지 브로커로 Redis를 사용해봤을 것이다. 그러다보니, In-Memory 기반이라던지 key-value로 구성되어있다던지 하는 내용들은 다 알고 있을 것이라고 생각한다.
하지만 최근 면접 후기를 듣고, 주변 사람들에게 Redis에 대해 물어봤을 때 Redis를 제대로 알고 사용한 사람이 굉장히 적었던 것 같다. 또 자신의 프로젝트 상황이나 성능을 고려해서 적용한 사람은 더욱 드물것이라고 생각한다.
그래서 이번 블로그를 통해 Redis를 사용할 때 최소한으로라도 알아야 하는 Redis의 특징을 알아보고자 한다.
Redis 자료구조
많은 사람들이 알고 있듯이, Redis는 Key-Value 형식의 구조를 갖고 있다. 하지만 이때 Value는 단순한 object 값이 아니라 Collection type을 가질 수 있는데, 덕분에 이러한 자료구조를 잘 활용하면 데이터 처리와 애플리케이션 성능을 크게 향상시킬 수 있다.
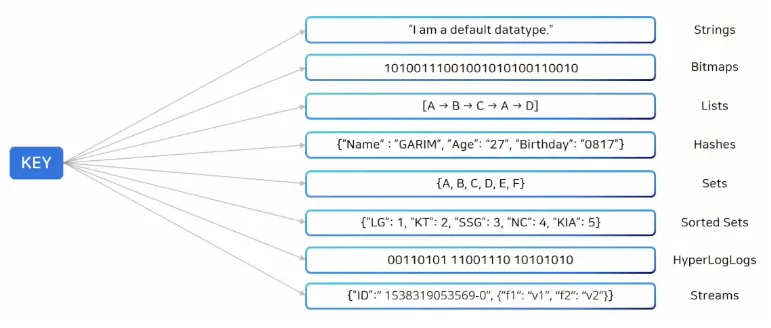
이들 중 유용하게 사용할 수 있는 몇가지만 알아보고 넘어가자.
1. Lists
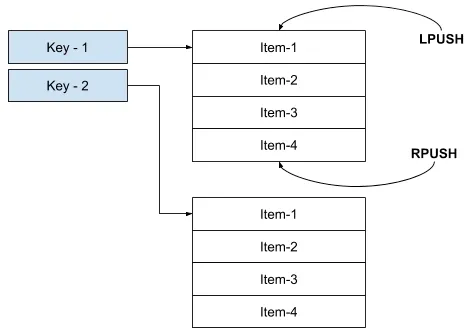
설명: Linked List 형태로, 순서가 있는 값들의 컬렉션
특징
- 추가 / 삭제 / 조회하는 것은 O(1)의 속도를 가지지만, 중간의 특정 index 값을 조회할 때는 O(N)의 속도를 가지는 단점이 있다.
- 즉, 중간에 추가/삭제가 느리다. 따라서 head-tail(좌우)에서 추가/삭제 한다. (LPUSH, RPUSH, LPOP, RPOP)
- 대기열(Queue)이나 스택(Stack) 구현에 유용하다
2. Sets
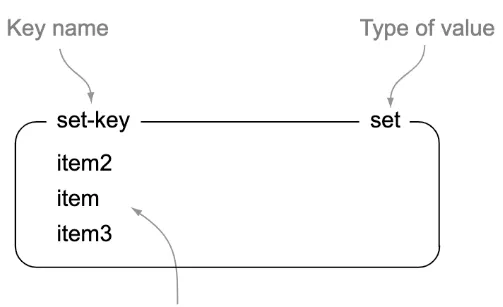
설명: 중복을 허용하지 않는 집합 자료구조
특징
- 중복된 데이터를 여러번 저장하면 최종 한번만 저장된다.
- 집합 연산 지원 (합집합 SUNION, 교집합 SINTER, 차집합 SDIFF)을 통해 Set간의 연산을 매우 빠른 시간내에 추출할 수 있다.
- 단, 모든 데이터를 전부 다 갖고올 수 있는 명령이 있으므로 주의해서 사용해야 한다.
3. Hashes
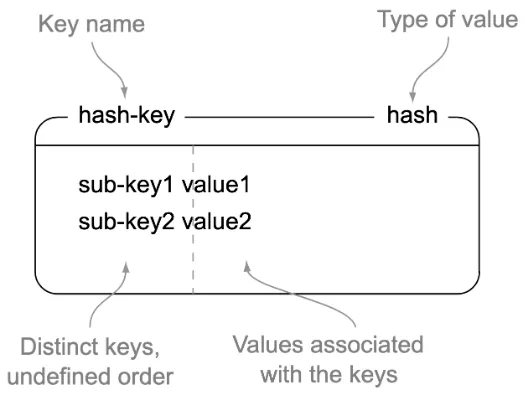
설명: field-value로 구성 되어있는 매핑 테이블
특징
- 객체나 구조체를 저장하는 데 유용
- 특정 필드만 업데이트 가능 (HSET, HGET)
- key 하위에 subkey를 이용해 추가적인 Hash Table을 제공하는 자료구조
- 메모리가 허용하는 한, 제한없이 field들을 넣을 수가 있다.
RDB VS AOF
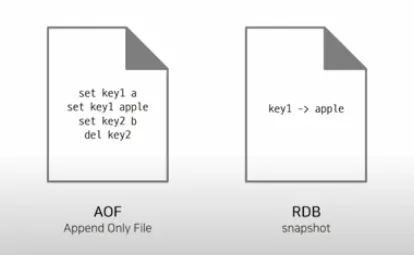
Redis는 메모리에 데이터를 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다. 하지만 알다시피, 메모리에 저장된 데이터는 사라질 가능성이 있다. 이를 보완하고자 Redis 는 관리하고 있는 데이터에 영속성을 제공한다. 즉, 메모리에 있는 데이터를 디스크에 백업하는 기능을 제공하며, RDB 방식이나, AOF 방식으로 백업할 수 있다.
RDB (Redis Database File)
개념: 메모리의 스냅샷을 찍어 디스크에 바이너리 파일로 저장
동작 방식
- 설정한 간격마다 전체 데이터를 덤프
- SAVE, BGSAVE 명령으로 수동 저장 가능
장점
- 빠른 시작 시간: 바이너리 형식으로 저장되어 로드 속도가 빠름
- 디스크 I/O 효율적: 주기적으로 저장하므로 디스크 부하 적음
단점
- 데이터 유실 가능성: 마지막 스냅샷 이후의 데이터는 손실될 수 있음
AOF (Append Only File)
개념: 모든 쓰기 연산을 순차적으로 로그 파일에 기록
동작 방식
- 각 쓰기 명령을 텍스트 형식으로 파일에 추가
- fsync 설정에 따라 디스크에 기록하는 주기 조절 가능
장점
- 데이터 복구 용이: 마지막 기록까지 복구 가능
- 사람이 읽을 수 있는 형식으로 저장되어 디버깅에 유용
단점
- 파일 크기 증가: 지속적인 기록으로 파일 크기 커짐
- 복구 시간 증가: 재시작 시 모든 명령 재실행 필요
선택 기준
- 데이터 안정성 우선: AOF 사용 권장
- 성능 및 디스크 효율성 우선: RDB 사용 권장
- 혼합 사용: 두 방식을 함께 사용하여 장점 극대화
⇒ 레디스는 일반적으로 AOF와 RDB를 동시에 사용하여 데이터를 백업한다.
예를 들면, 매일 7시마다 RDB 스냅샷을 생성하고, RDB 생성 이후에 변경되는 데이터는 AOF로 백업.
Single Thread
Redis는 싱글(단일)스레드로 작동하는 데이터베이스다. 이는 Redis가 모든 클라이언트의 요청을 하나의 스레드에서 처리한다는 의미인데, 그렇다면 싱글 스레드를 사용하는 이유는 무엇이고 성능은 어떨까?
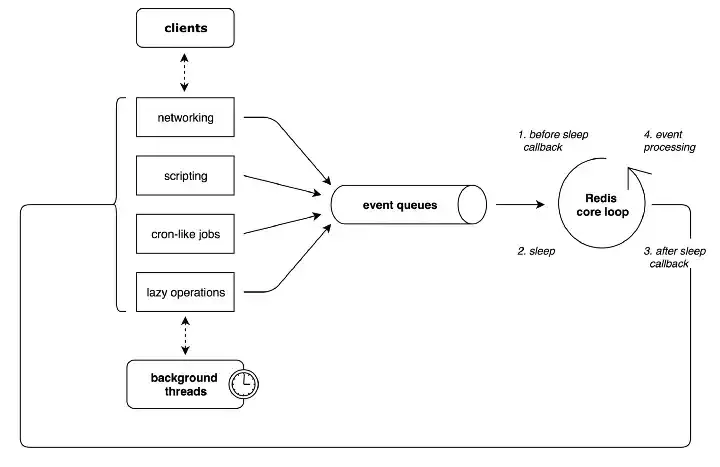
단일 스레드의 이유
- 간단한 설계: 복잡한 스레드 동기화 이슈 제거
- 빠른 성능: Context Switching 및 잠금(lock) 오버헤드 감소
- 일관성 유지: 동시성 문제로 인한 데이터 불일치 방지
성능에 대한 오해
- CPU 바운드 작업: 단일 스레드지만 대부분의 명령은 메모리 기반이어서 빠르게 처리 가능
- I/O 멀티플렉싱: 비동기 방식으로 클라이언트의 연결 관리
즉, Redis는 싱글 스레드로 동작하지만 이벤트 루프와 I/O 멀티플렉싱을 활용하여 다수의 클라이언트 요청을 비동기적으로 처리 하지만, 기본적으로 TCP 기반의 네트워크 모델을 따르기 때문에 네트워크 I/O 에서 병목이 생길 수 있는 가능성이 있다 Redis Pipeline을 통한 네트워크 병목 개선하기
주의 사항
- 복잡한 명령 회피: 대용량의 SORT, SUNION 등은 성능 저하 유발
- 멀티코어 활용 제한: 단일 인스턴스는 하나의 코어만 사용하므로 멀티코어 활용을 위해서는 여러 인스턴스를 실행하거나 클러스터링 필요
Redis 6.0 이후의 변화
- 멀티스레딩 도입: 일부 I/O 작업에 한해 멀티스레드 지원으로 성능 향상
- 핵심 로직 유지: 데이터 연산은 여전히 단일 스레드로 동작(일관성 유지)
왜 Redis?
그렇다면 왜 많은 사람들이 Redis를 사용할까? 사실 MySQL과 같은 RDBMS에도 캐싱 기능이 있고, Memcached와 같은 다른 NoSQL에도 데이터 저장을 할 수 있는데 말이다. (Spring은 Redis를 선택해왔다)
그래서, RDBMS와 Memcached를 Redis와 비교해보면서 Redis가 많이 사용되는 이유에 대해서 알아보고자 한다.
NoSQL VS RDBMS

위 글은 Spring Data Redis 공식 문서의 일부를 발췌한 것이다. 이 글에 따르면 Spring Data Redis를 사용하는 이유가 나오는데, 이를 통해 NoSQL의 장점을 알 수도 있다.
NoSQL 데이터베이스는 고성능을 제공하며, 특히 Key-Value 저장소는 데이터 액세스와 처리 속도가 매우 빠르다. 또 확장성 측면에서도 스키마리스 형태로 쉽게 수평적 확장이 가능하다. 속도와 확장성이 뛰어기 때문에 속도가 중요한 캐싱과 같은 역할에서는 RDBMS 보다 NoSQL이 적합하다는 것을 알 수 있다.
Redis VS Memcached
그렇다면 NoSQL 중 캐싱 전략에 자주 사용되는 Redis, Memcached 중 왜 Redis를 자주 선택할까?(Spring은 Spring Data Redis를 지원하며 기본적으로 Redis를 선택했다) 각각의 특징 분석과 함께 비교해보면서 그 차이를 알아보겠다.
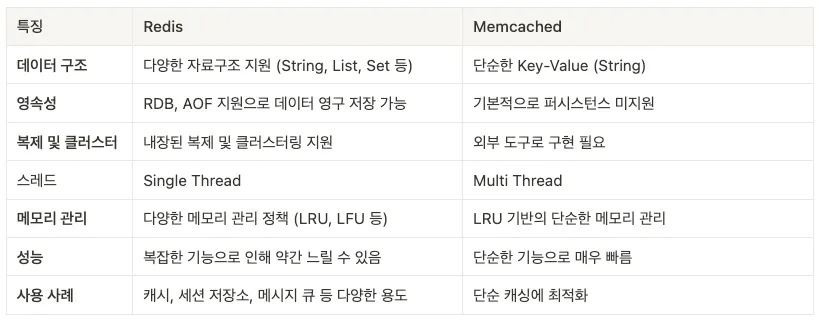
위 그림이 표로 Redis와 Memcached에 대해 비교해본 것인데 기본적으로는 둘 다 In-Memory key-value 방식의 NoSQL이다. 하지만 표로 확인할 수 있듯이, 디테일한 측면에서 많은 차이가 있다. 그럼 한번 비교해보자.
Redis > Memcached
1. 다양한 자료구조를 지원
String만 지원하는 Memcached에 비해 Redis는 더욱 다양한 자료구조를 지원하여 더 다양한 타입의 자료를 저장할 수 있습니다. 이는 Memcached에 비해 Redis가 가지는 강력한 장점 중 하나다.
2. 데이터 복구가 가능
프로세스의 돌발 종료, 서버 종료 등 돌발 상황에서 Memcached는 모든 데이터가 유실되지만, Redis는 데이터를 Disk에도 저장하기 때문에 메모리에서 유실된 데이터를 복구할 수 있다.
3. 다양한 Data Eviction 정책을 지원
Memcached는 LRU 알고리즘을 통한 Eviction을 지원한다. 하지만 Redis는 6가지 Eviction정책을 통해 더욱 세밀한 Eviction 제어가 가능하다.
Memcached > Redis
1. 멀티스레드를 아키텍처를 지원
Single Thread인 Redis에 비해 Memcached는 Multi Thread를 지원하기 때문에 서버 Scale up에 유리하다.
2. Redis에 비해 적은 메모리를 요구
HTML과 같은 정적인 데이터를 캐싱하는 것에는 Memcached가 유리하다. Redis는 Copy&Write 방식을 사용하기 때문에 실제 사용하는 메모리보다 더 많은 메모리를 요구한다.
그래서?
우선 기본적으로 Spring은 Spring Data Redis(SDR) 프레임워크를 지원하여 Redis 사용이 간편하고 확장성(복제 및 클러스터링), 자료구조 지원과 특히 데이터 복구와 영구 저장이 가능하다는 측면에서 강한 장점이 있기 때문에 Redis를 많이 이용한다.
또한 선호도에 있어서도 Redis가 압도적이다.
StackOverflow Redis vs Memcached
StackOverflow 올라온 Memcached와 Redis 중 어떤 것을 선택해야 하는지에 대한 압도적인 투표를 받은 답변에 따르면 거의 무조건 Redis를 이용하라고 한다.

주요 파트를 요약하자면, memcached의 성능 이점은 사소하고 작업 부하에 따라 다르다고 한다. Redis가 더 빠른 작업 부하도 있고, Redis가 할 수 있지만 memcached가 할 수 없는 훨씬 더 많은 작업 부하도 있다고 한다. 그래서 기능 면에서 큰 차이가 있고 성능 차이는 작기 때문에 Redis가 좋다는 의견이다.
이러한 이유로, Spring이 Redis를 선택한 것이라고 생각한다. 앞으로 프로젝트에서 Redis를 적용할 때는 이 정도는 고려해보고 적용해보자!