Facade 패턴 도입, 외부 연동과 DB 연동
Facade 패턴 도입, 외부 연동과 DB 연동
Facade(퍼사드) 패턴이란?
우선 이 블로그를 읽는 사람들이라면 Facade pattern 자체를 모르는 사람도 있을 것이라고 생각한다. Facade 패턴이란 복잡한 서브 클래스들의 공통적인 기능을 정의하는 상위 수준의 인터페이스를 제공하는 패턴이다. 이렇게 말하면 사실 이해가 잘 안될테니 이미지로 확인해보자.
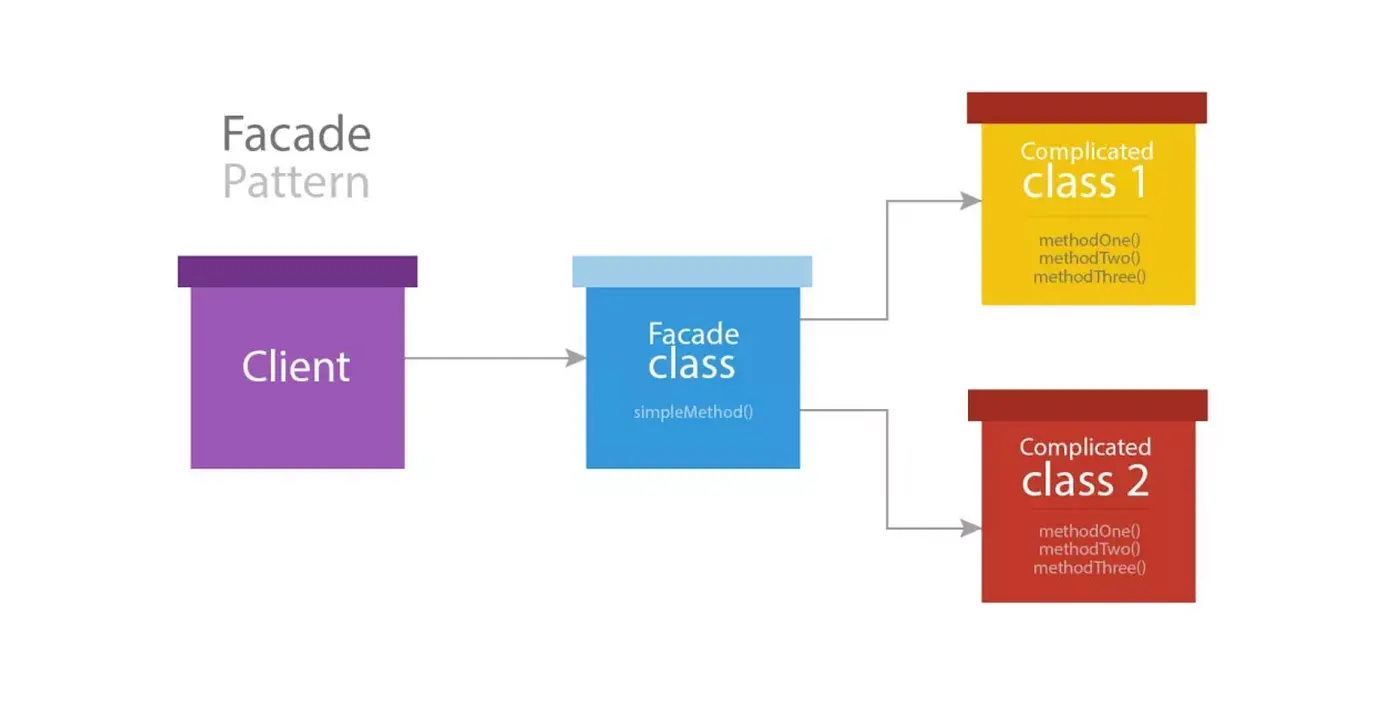
요런식으로 서브 클래스들 위에 층 하나를 입히는 것이라고 생각하면 된다. 이래도 이해가 안된다면 아래의 블로그 글을 참고해보면 도움이 될 것이다.
그러면 어디서 어떻게 도입할 수 있을까?
그러면 이 패턴을 프로젝트에서 어떻게 도입할 수 있을까?
나도 우테코 프리코스를 통해 처음 알게 되었는데, 당시에는 Java로 쌩코딩을 하는 상황이니 사용하는 패턴이라고 생각했고 프로젝트를 하면서는 쓸 일이 없다고 생각했다.
하지만 이번에 프로젝트를 하면서 층을 하나 더 추가하고 코드의 결합도를 낮추거나 여러 하위 클래스의 기능들을 상위 클래스에서 활용하면 좋겠다고 생각이 드는 파트가 있었다.
설명 전에 먼저 아래 사진을 보자(부끄러우니 대충 봐주면 좋겠다…)
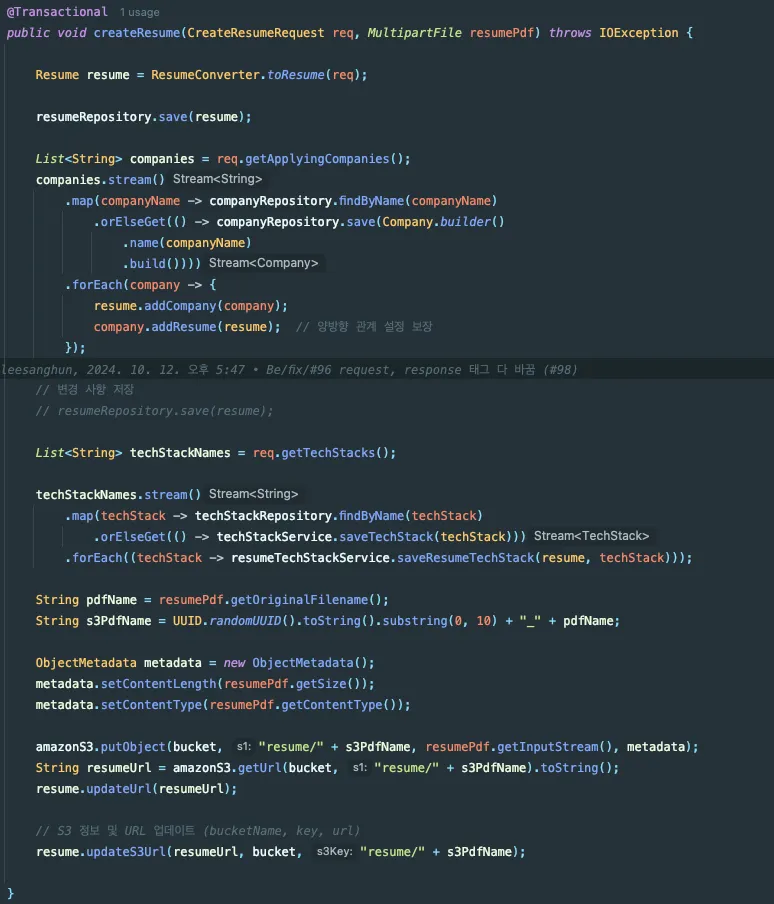
위 사진은 수정 전 이력서 생성 API에서의 Service code다. 해당 코드는 대충 봐도 코드 길이가 너무 길고 보기 힘들다는 것을 볼 수 있을 것이다.
지원할 회사, 기술 스택 등 이력서에 태그(해시태그와 같은)와 관련된 생성 로직, S3에 이력서 업로드 및 이력서에 관련 정보 업데이트 등의 코드가 한 함수에 작성되어 있어 당연히 SRP는 한참 어긴 코드다.
이 코드를 수정해야겠다고 생각하고 뛰어들었는데, 원칙없이 접근하기에는 너무 어렵고 수정 자체가 막막해서 몇가지 원칙을 세웠다.
- 무조건 하나의 Entity에 대한 하나의 Service Class를 만든다.
- 해당 Entity의 Repository는 특별한 경우를 제외하고는 해당 Entity의 Service에서만 다룬다.
- Service 간의 의존관계는 설정하지 않는다.
여기서 마지막 “Service간의 의존관계는 설정하지 않는다”는 왜 세운걸까? 나는 처음에 이력서와 태그의 관계에서 이력서가 상위 태그는 그 하위의 Entity로 생각하고 ResumeService에 태그 관련 Service를 의존성 주입하여 사용하면 된다고 생각했다.
하지만, 팀원과 리뷰를 하면서 문제가 발생할 수 있음을 느꼈는데 내용은 다음과 같다.
- 태그가 이력서의 하위 Entity라는 것은 나만 아는 생각이다. 해당 코드에 대해 처음 보게되는 팀원이 나와 똑같이 생각할 것이라는 보장이 없다.
- 만약 위와 같은 이유로 ResumeService에 Tag관련 Service를 의존한 상황에서 Tag관련 Service에 다시 ResumeService를 의존하면 순환 참조 문제가 발생한다.
위와 같은 이유로 Service 간의 의존관계 설정은 하지 않기로 했다. 그럼 Service간의 의존관계 설정을 하지 않으면 이력서 생성 함수에서 태그 생성 함수를 어떻게 호출할까?
Facade를 입히자
여기서 Facade pattern을 도입하면 좋겠다고 생각했다. Facade pattern으로 Controller와 Service 사이에 하나의 Layer를 더 두고 해당 Facade Class에서 다른 Service들을 의존성 주입하여 사용하면 위의 원칙을 지키면서도 정상작동하는 코드를 짤 수 있겠다는 생각에서였다.
그래서 Service간의 의존관계 설정이 필요할만한 모든 UseCase마다 Facade class를 만들어 사용하는 방식으로 적용했다.
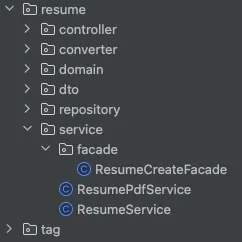
다음 사진처럼 Service에 facade라는 폴더를 하나 만들고, 내부에 UseCase에 알맞는 Facade를 두고 사용하면 된다. 나는 이력서 생성이라는 UseCase가 있었고, 해당 UseCase에 알맞는 ResumeCreateFacade를 만들어 사용했다.
그럼 적용한 코드는?
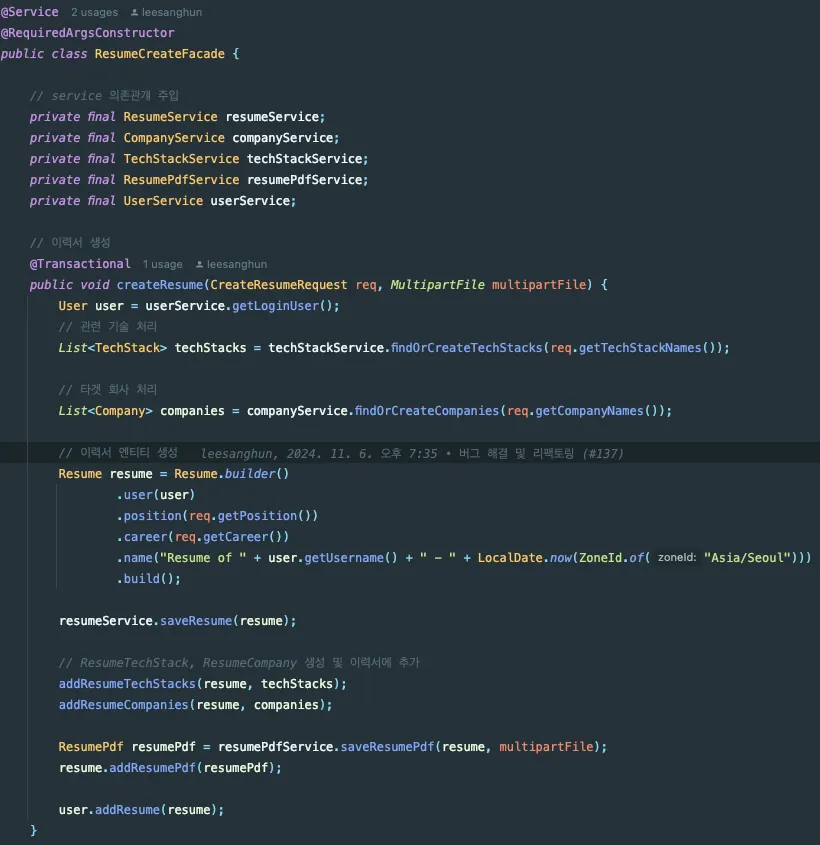
다음과 같이 필요한 Service와의 의존관계를 설정하고 해당 Service에서 필요한 함수들을 적절히 사용하니 훨씬 코드를 이해하기 쉽고 줄어들었다는 것을 볼 수 있다.
이때 다들 알겠지만 한 Transaction으로 묶어야 S3에 제대로 업로드되지 않았거나, 다른 로직에서 문제가 있을 때 해당 객체가 DB에 저장되지 않고 Rollback되니 꼭 알아두도록 하자.
외부 연동과 DB 연동
이게 외부 연동을 할 때 고민 포인트다. 이제 외부 연동을 할 때, DB 연동도 할텐데 오류 발생 시 트랜잭션 처리를 어떻게 할 것이냐. 이걸 잘 고민해야 한다.
당연히 흔히 발생하는 케이스는 아래 두 가지가 있다.
- 외부 연동에 실패했을 때, 트랜잭션 롤백
- 외부 연동은 성공했는데 DB 쪽에서 실패에서 롤백
외부 연동에 실패했을 때, 트랜잭션 롤백
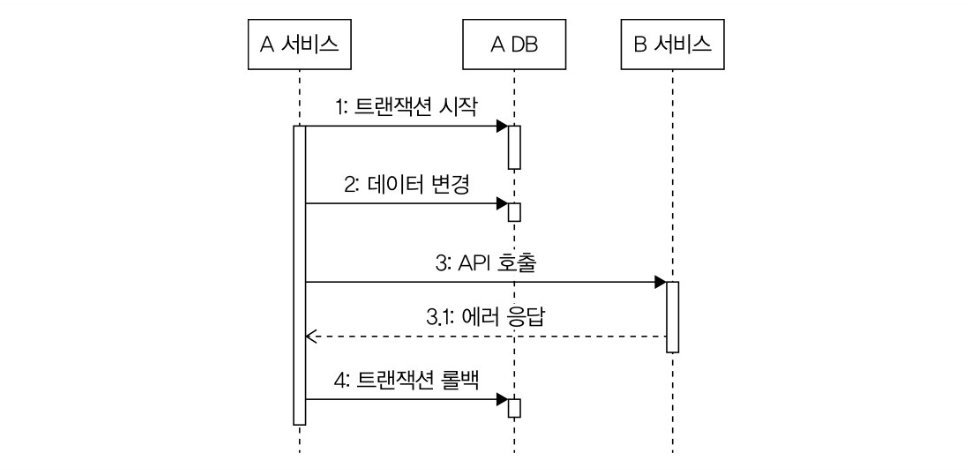
트랜잭션 범위 안에서 외부 연동에 실패했을 때는? → 트랜잭션 롤백이 된다. 당연히 이 경우에는 변경된 데이터가 DB에 남지 않는다. 단순하지만 간단한 방법이다.
근데 이 경우에 읽기 타임아웃에 의한 실패로 인해 트랜잭션이 롤백된다면 외부 서비스가 실제론 성공했을 가능성을 염두해둬야 한다. 외부 연동 서비스가 멱등하다면 신경을 안써도 될 거 같다.
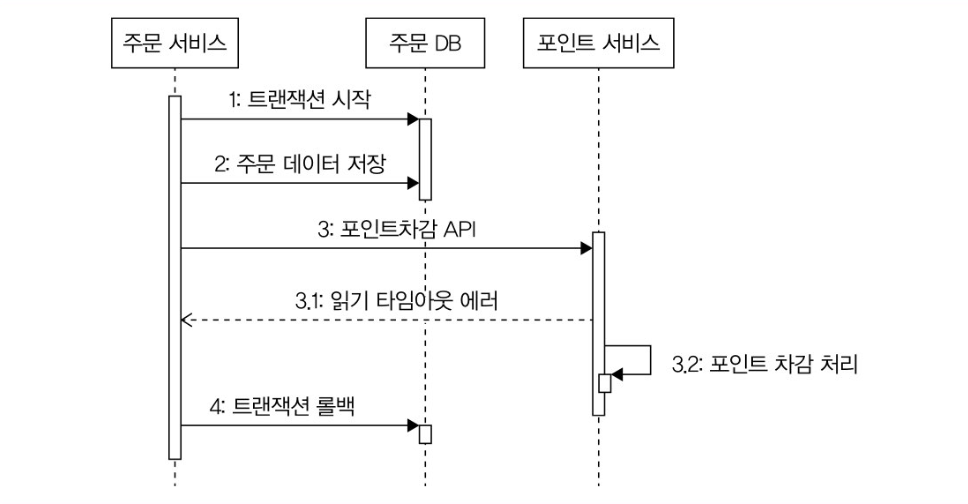
위와 같은 상황에서 읽기 타임아웃으로 인해 롤백을 했다면 아래 두 가지 방식을 검토해야한다.
- 일정 주기로 확인해서 데이터 보정하기
- 성공 확인 API 호출하기
일정 주기로 확인해서 데이터를 보정하는 방법은 스케쥴링을 활용해서 데이터 일치 여부를 확인해서 보정하는 방법이다. 수동 혹은 자동으로 보정해주면 된다.
성공 확인 API를 호출하는 방법은 읽기 타임아웃이 발생한 경우, 일정 시간 후 에 이전 호출이 실제로는 성공했는지 확인할 수 있는 API를 호출한다는 뜻이다. 성공이면? -> 트랜잭션 지속, 실패면? -> 트랜잭션 롤백
이 방식의 변형으로 취소 API를 호출하는 방법도 있다. 개인적으로 성공 API이던 취소 API이던 둘 다 문제가 있다고 생각하는데, 계속 트랜잭션을 열어두고 이 작업을 하겠다는 것이기 때문에 커넥션 이 그 시간동안 과도하게 잡아먹힌다고 생각한다.
그래서 개인적으로는 정기적으로 데이터 일치를 확인하거나 비동기 메시징 시스템 을 쓰는 등 커넥션 풀을 잡아먹지 않는 다른 방법을 고려하는 편이 낫다고 생각한다.
외부 연동은 성공했는데 DB 연동에 실패해서 트랜잭션을 롤백
외부 연동은 성공했지만, DB 연동에 실패해서 롤백되는 경우에는 취소 API를 호출해서 외부 연동을 이전 상태로 되돌리는 것이 필요하다. DB 연동에 실패했기 때문에, 이 경우에는 성공 확인 API를 호출해도 의미가 없다.
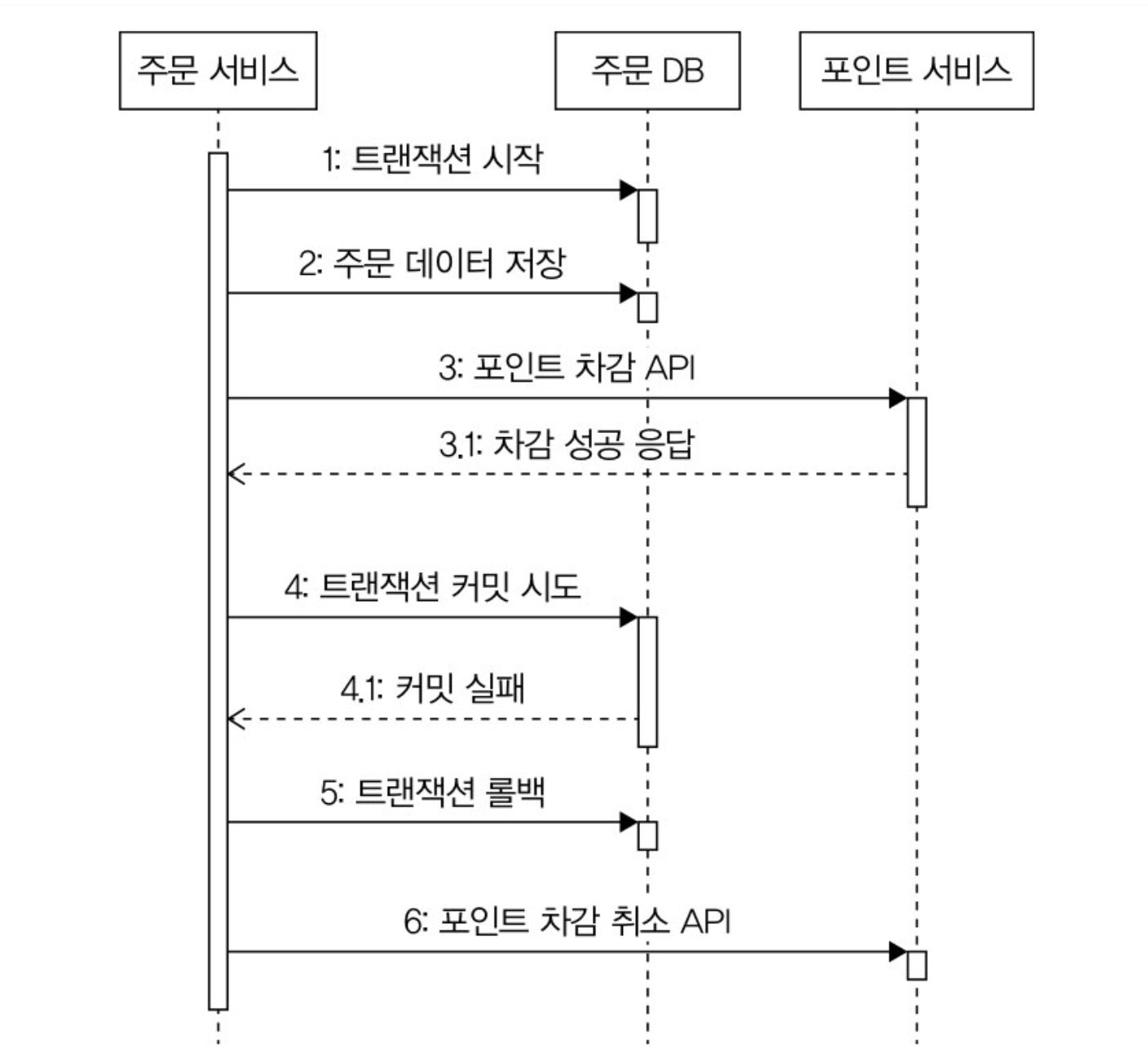
이것도 취소 API 가 없거나 취소에 실패할 수도 있어서 데이터 일관성이 중요하면 일정 주기로 데이터가 맞는지 비교하는 프로세스를 갖춰야 한다.
외부 연동이 느려질 때 DB 커넥션 풀 문제
DB 트랜잭션 범위 안에서 외부 연동을 할 때, 외부 연동이 느려지면 커넥션 풀 부족 현상이 발생할 수 있다. 예를 들어, 기능 실행에 5초가 걸리는 상황이 있다고 치자.
- 커넥션 풀에서 커넥션을 가져온다.
- 0.1초가 걸리는 DB 쿼리를 실행한다.
- 외부 연동 API(4.8초 정도 실행 가정)를 호출한다.
- 0.1초가 걸리는 DB 쿼리를 실행한다.
- 커넥션을 풀에 반환한다.
이 시나리오에서 외부 연동을 제외하면, 실제 DB 커넥션이 사용되는 시간이 0.2초에 불과하다. 근데 외부 연동이 4.8초가 걸리면서 커넥션이 5초가 걸린다. 즉, DB 쿼리는 안 날리는 동안 커넥션은 점유된 상태라는 거다.
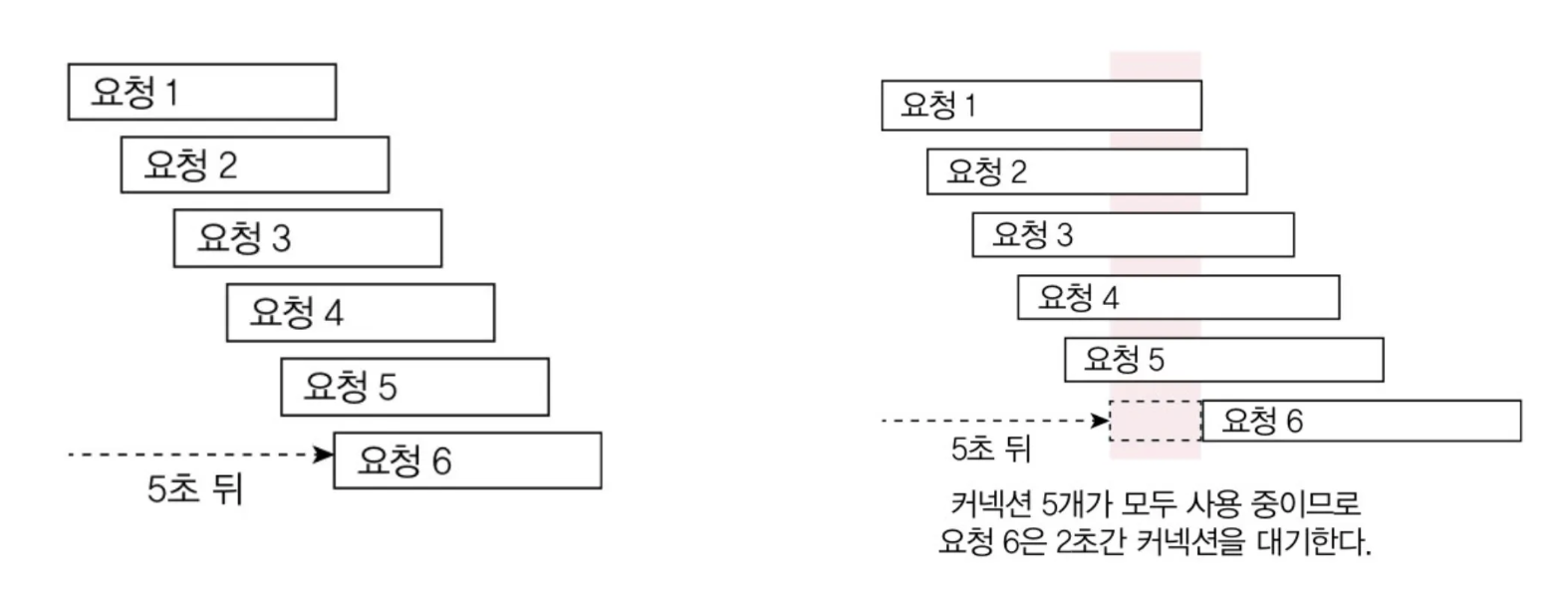
이렇게 커넥션이 외부 연동에 점유되면, 당연히 문제가 있다.
- 외부 연동 시간이 늘어날 수 있는거고
- 커넥션 풀은 무한대가 아니기 때문에 트래픽이 많으면 포화될 수 있다.
이제 그래서 DB 연동과 무관하게 외부 연동을 실행할 수 있다면, DB 커넥션을 사용하기 전이나 후에 외부 연동을 시도하는 방안도 고려해볼 수 있다. 이렇게 하면 외부 연동이 길어지더라도 DB 커넥션 풀이 포화되는 상황을 방지할 수 있다. 당연히, 트랜잭션 범위 밖에서 실행되기 때문에 커밋 이후 외부 연동에 실패하면 롤백이 불가능하다. → 후처리를 고려해야 한다는 뜻이다.
예) 보상 트랜잭션, 데이터 후보정
S3와 DB 연동 시 고려사항
이력서 생성과 같은 경우, S3에 파일을 업로드하고 DB에 메타데이터를 저장하는 과정에서 다음과 같은 케이스들을 고려해야 한다.
Case 1: 트랜잭션 내에서 S3 업로드
1
2
3
4
5
6
7
8
9
10
11
12
@Transactional
public void createResume(ResumeCreateRequest request) {
// 1. DB에 이력서 정보 저장
Resume resume = resumeService.save(request);
// 2. S3에 파일 업로드
String s3Url = s3Service.uploadFile(request.getFile());
// 3. S3 URL로 이력서 정보 업데이트
resume.updateS3Url(s3Url);
resumeService.save(resume);
}
장점: 데이터 일관성 보장 단점: S3 업로드가 느릴 경우 DB 커넥션을 오래 점유
Case 2: S3 업로드 후 DB 저장
1
2
3
4
5
6
7
8
public void createResume(ResumeCreateRequest request) {
// 1. S3에 파일 업로드
String s3Url = s3Service.uploadFile(request.getFile());
// 2. DB에 이력서 정보 저장 (S3 URL 포함)
Resume resume = new Resume(request, s3Url);
resumeService.save(resume);
}
장점: DB 커넥션 점유 시간 최소화 단점: S3 업로드는 성공했지만 DB 저장 실패 시 S3에 불필요한 파일 남음
Case 3: 이벤트 기반 처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@Transactional
public void createResume(ResumeCreateRequest request) {
// 1. DB에 이력서 정보 저장 (상태: PENDING)
Resume resume = resumeService.saveWithPendingStatus(request);
// 2. S3 업로드 이벤트 발행
eventPublisher.publishEvent(new ResumeUploadEvent(resume.getId(), request.getFile()));
}
@EventListener
public void handleResumeUpload(ResumeUploadEvent event) {
try {
// S3 업로드
String s3Url = s3Service.uploadFile(event.getFile());
// DB 상태 업데이트
resumeService.updateS3Url(event.getResumeId(), s3Url);
} catch (Exception e) {
// 실패 시 상태를 FAILED로 변경
resumeService.updateStatus(event.getResumeId(), ResumeStatus.FAILED);
}
}
장점: 비동기 처리로 성능 향상, 재시도 로직 구현 가능 단점: 복잡성 증가, 이벤트 처리 실패 시 데이터 불일치 가능성
결론
S3와 DB 연동의 경우, Case 2 (S3 업로드 후 DB 저장) 방식을 선택하는 것이 가장 적절해 보인다.
이유:
- 성능: DB 커넥션을 오래 점유하지 않아 커넥션 풀 부족 문제를 방지
- 단순성: 복잡한 이벤트 처리나 보상 트랜잭션 없이도 구현 가능
- 실용성: S3에 불필요한 파일이 남는 것은 주기적인 정리 작업으로 해결 가능
다만, 데이터 일관성이 매우 중요한 경우라면 Case 1을 선택하되, S3 업로드 타임아웃을 적절히 설정하고 커넥션 풀 크기를 충분히 확보해야 한다.