다중 프로그래밍과 동기화
다중 프로그래밍과 동기화
다중 프로그래밍
다중 프로그래밍(Multi-programming)이란 CPU 작업과 입출력 작업을 병행하는 것이다. CPU 이용과 처리량을 향상시킬 수 있다.
-위키백과-
이러한 다중 프로그래밍의 목적은 CPU 이용을 최대화하기 위하여 항상 어떤 프로세스가 실행되도록 하는 데 있다. 각 프로그램이 실행되는 동안 사용자가 상호 작용할 수 있도록 프로세스들 사이에서 CPU를 빈번하게 교체한다면 시분할의 목적을 이룰 수 있다.
프로세스란
간단하게 프로세스의 개념에 대해 짚고 넘어가자. 프로세스란 실행 중인 프로그램을 의미한다. 그렇다면 실행 중인 프로그램은 무엇을 의미하는 것일까? 우선 프로그램의 개념부터 알아보자.
프로그램은 기본적으로 컴퓨터가 특정 작업을 수행하기 위해 따르는 명령어의 모음이라고 한다. 하지만 중요한 것은 이게 아니다. 컴퓨터 공학에서 프로그램에서의 프로그램의 중요한 의미는 비휘발성 메모리 즉 storage에 저장한 정적인 상태의 파일을 의미한다.
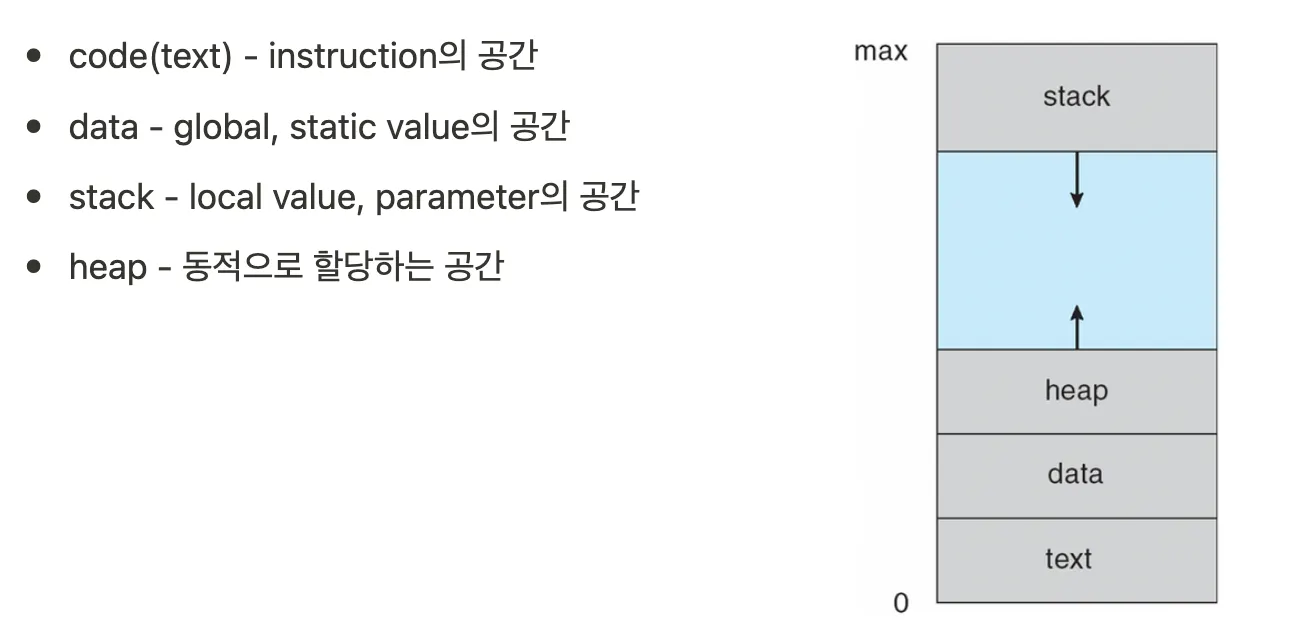
그렇다면 프로세스는 이 storage에 존재하는 정적 파일을 메모리에 올려 code, data, stack, heap 영역으로 구성된 메모리 공간을 할당받은 상태 다시말해 실행 중인 상태인 프로그램을 의미한다.
메모리 구조
프로세스 상태
우선 프로세스의 상태에 대해 알아보자. 프로세스는 실행되면서 상태가 변한다. 그리고 이 프로세스의 상태는 부분적으로 그 프로세스의 현재 활동에 따라 정의된다. 프로세스의 상태들은 다음과 같다(임의적인 이름이고, OS마다 다르게 부를 수 있다).
- New(새로운) : 프로세스가 생성 중이다.
- Running(실행) : 명령어들이 실행되고 있다.
- Waiting(대기) : 프로세스가 어떤 사건이 일어나기를 기다린다.
- Ready(준비 완료) : 프로세스가 처리기에 할당되기를 기다린다.
- Terminated(종료) : 프로세스의 실행이 종료되었다.
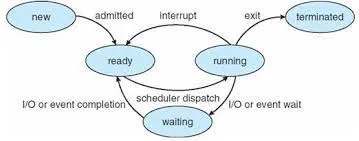
새로운 프로세스가 만들어지면, 준비 완료 상태에 놓이게 된다. 이 준비 완료 상태의 프로세스는 인터럽트나 이벤트에 의해 호출되게 되고 스케줄러 프로세스는 실행 상태에 놓인다. 실행된 프로세스는 더 이상 실행할 게 없으면 종료 상태로, 입출력이나 이벤트를 실행해야 하면 대기 상태가 된다. 대기 중인 프로세스는 대기 상태가 끝나면 다시 준비 완료 상태가 되고 이후 실행된다.
중요한 것은, 한 처리기 상에서 오직 하나의 프로세스만 실행될 수 있다는 것이고, 실행되지 않은 많은 프로세스들은 준비완료 상태나 대기 상태에 있다는 것이다.
스케줄링 큐
프로세서는 일생 동안 다양한 스케줄링 큐들 사이를 이주한다. 프로세스를 스케줄링 하기 위해서는 세 가지 큐가 존재한다.
- Job queue(잡 큐 or 작업 큐)
- Ready queue(준비 완료 큐)
- Device queue(장치 큐)
Job queue
💡 In system software, a job queue (a.k.a. batch queue, input queue), is a data structure maintained by job scheduler software containing jobs to run.
- Wikipedia -
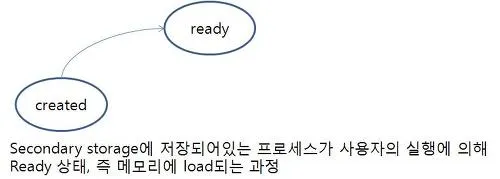
프로세스는 생성되어 시스템에 들어오면 잡 큐에 놓여진다. 이 큐는 시스템 안의 모든 프로세스로 구성되고 스토리지에 존재한다. 좀 더 자세하게 설명하자면, 스케줄러가 스토리지에 존재하는 프로세스(이를 프로그램이라고 부름) 중 어떤 프로세스를 주 메모리로 load할 지 결정하고 이 역할을 하는 스케줄러를 장기 스케줄러 또는 잡 스케줄러라고 부른다. 이때 프로그램이 메모리로 load될 때 스토리지에 형성되어 있는 큐가 바로 Job queue다.
Ready queue
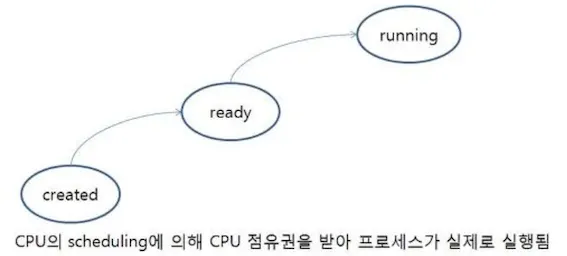
준비 완료 큐는 메인 메모리 상에 존재하고, 준비 완료 상태에 있는 프로세스들이 연결 리스트 상태로 저장되어 있는 큐이다. 준비 완료 큐는 현재 메모리에 올라와있는 프로세스 중 어떤 프로세스가 CPU점유권을 가질 지 결정해주는 단기 스케줄러(혹은 CPU 스케줄러)에 의해 관리된다. 쉽게 말해, 메모리에 load된 프로세스들이 모여 있는 큐이고 현재 메모리 내에 있으면서 CPU를 할당받기 위해 기다리고 있는 프로세스들이 모여있는 큐라고도 볼 수 있다.
Device queue
Ready Queue가 메모리에 있다면 Device Queue는 Device Controller에 있다. Device Controller는 쉽게 말해서 하드웨어 그 자체이다(현재 중요한 내용이 아니여서 짧게 설명하고 넘어가겠다).
스레드란
스레드(thread)란 CPU 활용의 기본 단위로서 프로세스 내에서 실제로 작업을 수행하는 주체를 의미한다. 모든 프로세스에는 한 개 이상의 스레드가 존재하여 작업을 수행하고, 하나의 프로세스는 내부에 여러 개의 스레드를 가질 수 있다. 이때 두 개 이상의 스레드를 가지는 프로세스를 멀티스레드 프로세스(multi-threaded process)라고 한다.
프로세스 VS 스레드
위 글을 통해 짐작했겠지만 스레드는 프로세스보다 더 작은 개념이라고 볼 수 있다. 리눅스에서는 스레드를 Light Weight Process라고 부르기도 한다. 그렇다면, 프로세스와 스레드는 근본적으로 어떻게 다를까?
1. 데이터 접근
프로세스에서는 서로의 데이터를 공유하기 위해서는 IPC 통신(공유 메모리나 메시지 패싱)을 이용해야 한다. 프로세스는 생성될 때 각자의 메모리 공간을 가지니 당연한 것이다. 하지만, 스레드는 프로세스 내부에 존재하기에 프로세스의 데이터 영역에 접근이 가능하다. 그리고 스레드들끼리 서로의 데이터에 접근 가능하다. IPC 필요없이 프로세스의 데이터를 가져올 수 있다.
2. 메모리 공간
스레드는 일종의 함수로 구현된다. 스레드도 함수라서 데이터(지역 변수)를 다루고, 데이터를 관리하기 위해 stack 메모리 영역을 가진다. 이 stack공간은 프로세스가 가지는 stack 메모리 영역과는 별개이며, 스레드의 메모리 영역을 thread stack이라고 부른다. 프로세스는 메모리 영역을 크게 4가지(code, data, stack, heap)으로 나눌 수 있지만, 스레드는 thread stack 메모리 공간만 갖게된다.
다중 코어 프로그래밍
과거와는 다르게 현대의 컴퓨터에는 컴퓨터 칩 하나에 단일 CPU가 있는 것이 아니라 여러 개의 CPU(코어)를 넣는다. 하나의 코어는 오직 하나의 스레드만 실행할 수 있기 때문에 단일 코어 시스템에서 병행성은 단순히 스레드의 실행이 시간 순서대로 교대로 진행된다는 것을 의미했다. 하지만 여러 코어를 가진 시스템에서는 병렬적으로 여러 스레드들을 실행시킬 수 있다는 것을 의미한다.
병행처리 VS 병렬처리
다중 프로그래밍, 동기화 등에 대해 공부하게 되면 병행 처리와 병렬 처리라는 용어를 많이 보게 된다. 글자도 비슷하고 의미도 비슷하다보니 더 헷갈리고 심지어는 그 차이에 대해 알지 못하고 혼용해서 사용하기도 한다. 이번 챕터를 통해 병행과 병렬의 의미를 간단하게 알아보자.
병행(Concurrency)

병행 처리라는 용어는 주로 Single Core일 때 사용하는데, 물리적으로 한 프로세스가 CPU를 점유하고 있다면 다른 프로세서는 CPU를 점유할 수 없게 된다. 이때 이런 물리적인 상황을 극복하기 위해 소프트웨어적으로 작업을 번갈아가며 실행하게 되고 이로 인해 우리 눈에는 동시에 실행되는 것처럼 보이게 된다. 이를 병행 처리라고 한다.
병렬(Parallelism)
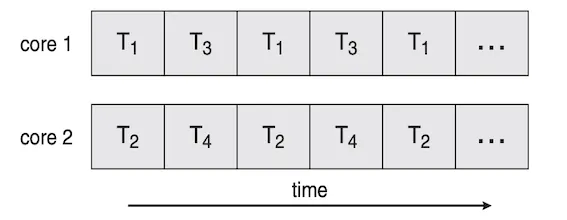
병렬 처리는 병행 처리와는 달리 물리적으로 여러 개의 작업을 동시에 수행하는 것이며 당연히 Multi Core에서만 동작 가능하다(한 CPU는 하나의 프로세서만 점유 가능). 여러 개의 코어에 작업을 각 코어로 분산시켜서 동시에 작업하며 이러한 개념을 병렬 처리라고 한다.
프로세스 동기화
여러 개의 스레드를 생성해서 하나의 전역변수를 이용해서 값을 출력하는 코드를 짜봤다면, 원하는 값이 출력되지 않고 이상한 값이 출력되는 경험을 해본적이 있을 것이다. 이는 앞서 말했듯이 스레드는 프로세스의 데이터 영역을 공유하기 때문에 전역변수를이용하는 코드를 짠다면 공유된 자원을 동시에 접근하는 것이기에 문제가 발생할 수 있는 것이다. 이번 동기화 챕터를 통해 여러 프로세스나 스레드가 같은 데이터를 공유할 때 이 데이터의 무결성에는 어떤 문제가 발생하는 지 알아보고 해결 방법 또한 알아보자.
생산자-소비자 문제
생산자 코드:
1
2
3
4
5
6
7
while(true){
while(counter == BUFFER_SIZE)
; /*do nothing*/
buffer[in] = next produced;
in = (in+1) % BUFFER SIZE;
counter++;
}
소비자 코드:
1
2
3
4
5
6
7
while(true){
while(counter ==0)
; /*do nothing*/
next consumed = buffer[out];
out = (out + 1) % BUFFER SIZE;
counter--;
}
0을 초기화된 counter, 버퍼에 새 항목을 추가할 때마다 counter 값을 증가시키고 버퍼에서 꺼낼 때마다 counter 값을 감소 시킨다.
위와 같은 생산자와 소비자 코드는 개별적으로는 올바를지라도, 병행적으로 수행시키면 올바르게 작동하지 않는다. 예를 들어, counter의 현재 값은 5이고 생산자와 소비자가 각각 counter++; counter—; 을 각각 병행하게 실행한다고 가정하자.
1
2
3
4
5
6
T0 : 생산자가 register1 = counter를 수행{register1 = 5}
T1 : 생산자가 register1 = register1 + 1을 수행 {register1 = 6}
T2 : 소비자가 register2 = counter를 수행 {register2 = 5}
T3 : 소비자가 register2 = register2 - 1을 수행 {register2=4}
T4 : 생산자가 counter = register1을 수행 {counter=6}
T5 : 소비자가 counter = register2를 수행 {counter=4}
이 두 개의 명령이 수행되고 나면 counter 값은 4가 된다(경우에 따라 5나 6일 될 수도 있음). 올바른 값은 5여야 하는데 실행이 분리되지 않아 올바른 값을 도출할 수 없는 것이다.
즉 두 개의 프로세스가 동일한 변수 counter를 접근하도록 허용하여 조작하고 접근이 발생한 특정 순서에 의존하는 경쟁 상황에 놓여 부정확한 결과를 얻게 된 것이다.
우리는 이러한 경쟁 상황으로부터 보호하기 위해, 동시에 공유된 자원에 접근할 때 프로세스들을 동기화 되도록 해야하는 것이다.
임계구역 문제(critical section)
임계 구역(critical section) 또는 공유변수 영역은 병렬컴퓨팅에서 둘 이상의 스레드가 동시에 접근해서는 안되는 공유 자원(자료 구조 또는 장치)을 접근하는 코드의 일부를 말한다. 임계 구역은 지정된 시간이 지난 후 종료된다. 때문에 어떤 스레드(태스크 또는 프로세스)가 임계 구역에 들어가고자 한다면 지정된 시간만큼 대기해야 한다. 스레드가 공유자원의 배타적인 사용을 보장받기 위해서 임계 구역에 들어가거나 나올때는 세마포어 같은 동기화 매커니즘이 사용된다. -위키백과-
동기화에 관한 논의를 하려면 임계구역 문제를 알아야 한다. 각 프로세스는 임계 구역이라고 부르는 코드 부분을 포함하고 있고, 그 안에서는 다른 프로세스와 공유하는 변수를 변경하거나, 테이블을 갱신하거나 파일을 쓰는 등의 작업을 수행한다.
이 시스템의 가장 중요한 특징은 “한 프로세스가 자신의 임계구역에서 수행하는 동안에는 다른 프로세스들은 그들의 임계구역에 들어갈 수 없다”는 것이다. 임계구역 문제는 프로세스들이 협력할 때 사용할 수 있는 프로토콜을 설계하는 것이고 이에 따라 각 프로세스들은 자신의 임계구역으로 진입하려면 진입 허가를 요청해야 한다.
1
2
3
4
5
6
7
8
9
10
do {
entry section //입장 구역
critical section // 임계 구역
exit section //퇴장 구역
remainder sectoin // 나머지 구역
}while(true)
위와 같은 방식으로 critical section 에 진입하는 요청을 하는 코드 부분을 entry section, 퇴장하는 요청을 하는 코드 부분을 exit section이라고 한다.
Mutex, Semaphore를 알고 있다면 쉽게 이해할 수 있을 것이다.
Critical Section vs Critical Region
이번에 알아볼 것은 Critical Section 과 Critical Region의 차이점이다. 위에서 Critical Section에 대해 이야기 해보았다. 그런데 인터넷에 Critical Section에 대해 검색하면 Critical Region이라는 단어가 자주 보이고, 혼용되어 쓰이는 것을 확인할 수 있다. 그렇다면, Critical Section vs Critical Region을 구글링해서 둘의 차이점에 대해 알아보자.

위의 구글링 결과를 통해 알아보면 단순히 critical region은 critical section이 확장된 개념 정도로 생각하기 마련이다.
하지만 이것은 critical section과 critical region의 차이라고 볼 수 없다.
차이점
critical section과 critical region의 차이점은 section은 둘 이상의 스레드가 동시에 접근해서는 안되는 공유 자원(자료 구조 또는 장치)을 접근하는 “코드”를 의미하는 것이고 region은 이때의 “공유 자원”(이때 자원은 공유 메모리(S/W)와 (H/W))을 의미하는 것이다.
예시를 통해 둘의 차이점에 대해 직관적으로 이해해보자. 사용자가 핸드폰으로 카카오톡과 인스타그램을 사용하고 있다고 가정해보겠다.
카카오톡이나 인스타 DM을 사용자에게 사용자의 친구 A와 친구 B가 동시에 메시지를 보냈고 카카오톡이 아주 약간 더 빠르게 메시지를 받았고, dm이 아주 조금 늦었다고 가정한다.
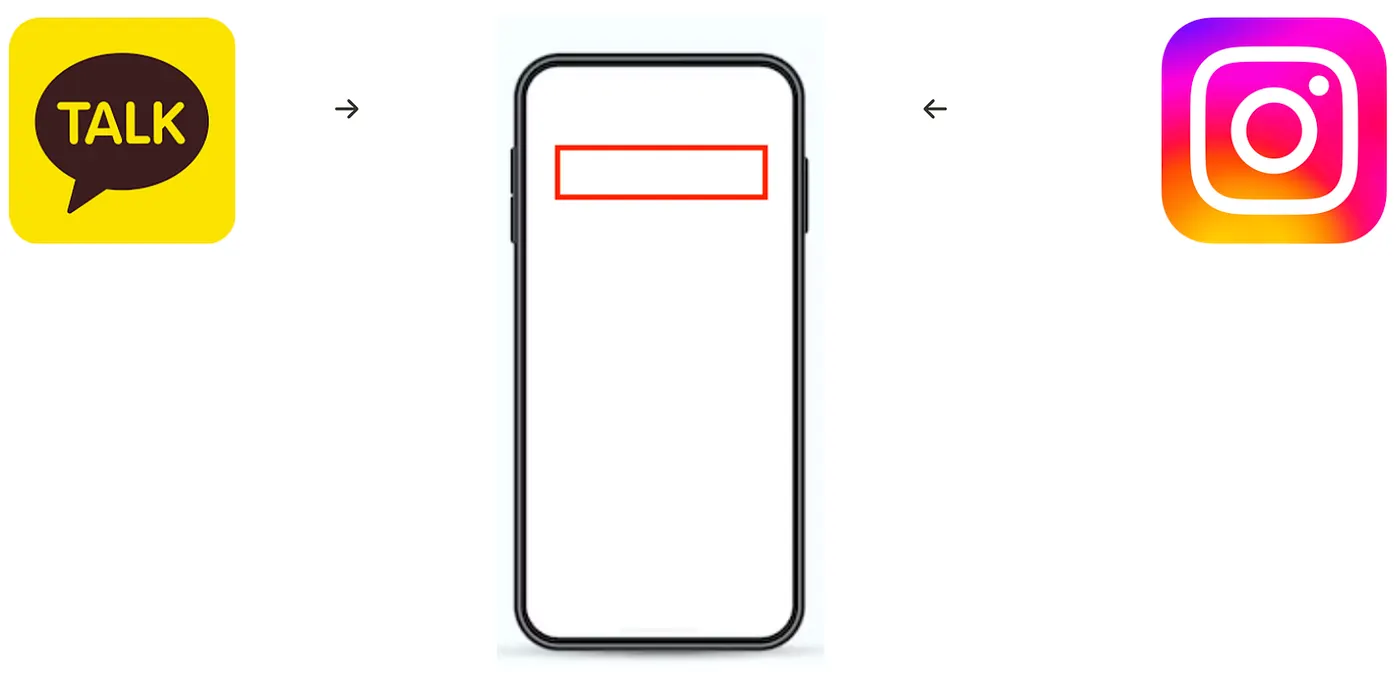
핸드폰의 LCD Buffer(화면에 표시가 될 이미지나 텍스트를 저장하는 메모리 영역)에는 카카오톡의 메시지 내용을 담았다가 보여주고, 이후 인스타 DM의 내용을 보여줄 것이다. 이때 카카오톡 메시지를 출력하기 위해 카카오톡이 먼저 화면 위쪽 영역을 사용하고, 카카오톡이 일을 마치면 DM이 화면 위쪽 영역을 사용할 수 있을 것이다.
이때 이 LCD 화면 or LCD Buffer(공유 자원)가 바로 “Critical Region”이고 이 자원에 진입 컨트롤을 하는 코드가 바로 “critical section”이다. 이 둘 간의 차이를 이해하여 둘을 혼용하지 않고 사용할 수 있어야 한다.
마치며
다중 프로그래밍의 개념부터 다중 프로그래밍을 할 때 나타날 수 있는 문제와 이를 해결하기 위한 방식에 대해 알아보았다. 현대의 다중 코어 구조의 시스템으로 인해 CPU를 효율적으로 사용하기 위해 다중 프로그래밍 구조를 만들게 되었고, 이를 통해 더 빠르고 효율적으로 CPU를 사용할 수 있게 되었다.
하지만, 공유된 자원을 동시에 접근하여 경쟁 상황에 놓이게 되는 문제도 발생하게 되었는데 이를 해결하기 위해 임계구역을 설정하여 프로세스를 동기적으로 실행해야 이 문제를 해결할 수 있다는 것을 알게 되었다.
기본적으로 OS를 공부하며 배우게 되는 Mutex, Semaphore에서 이용하는 Locking 또한 이러한 구조를 갖는다는 것을 이해한다면 멀티 프로세싱, 멀티 쓰레딩을 이해하고 적용하는 것에 도움이 될 것이라고 생각한다.