외부 연동이 문제일 때 살펴봐야 할 것들 [주니어 백엔드 실무지식]
외부 연동이 문제일 때 살펴봐야 할 것들 🔗
인터넷 초창기와 달리 외부 연동이 서버 개발에 있어 필수 요소가 되었고, 마이크로서비스를 도입하는 기업이 늘면서 내부 서비스 간 연동도 복잡해지고 있다. 이로 인해, 신경 써야 할 품질 문제도 늘고 있다.
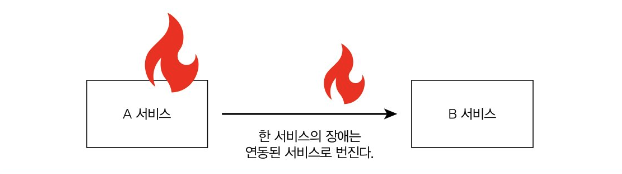
책의 사례에서는 A은행이 가입 과정에서 필요한 정보 인증을 위해 외부 서비스를 호출했는데, 외부 서비스가 몰려드는 트래픽을 감당하지 못하면서 장애가 발생했다. 이렇게 외부 서비스의 장애에 의해 우리 서비스가 영향을 받게 되고, 만약 서비스 간 연동이 많아질수록 연동 시스템의 품질을 신경써야 한다.
당연히 완전히 차단하기는 힘들지만, 그 영향을 줄이고 안정적인 서비스를 운영하는 방법에 대해 알아보자.
타임아웃 ⏰
외부 연동에서 가장 중요한 설정 중 하나는 타임아웃이다. 타임아웃은 응답 시간과 깊이 관련되어 있어 중요하다. 연동 서비스를 호출할 때 타임아웃을 적절하게 설정하지 않으면, 연동 서비스에 장애가 발생했을 때 서비스 전체의 품질이 급격히 나빠질 수 있다.
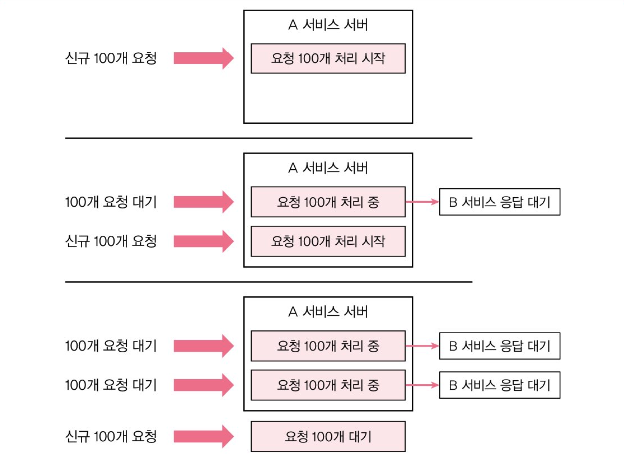
해당 그림처럼 연동 서비스에 적절한 타임아웃을 설정하지 않으면 내 서버의 쓰레드가 잡아먹히게 되고 새로운 요청에 대한 처리를 못하게 된다. 즉, 처리량이 급감하고 부하가 배가 되면서 문제가 발생할 수 있다는 것이다.
이런 문제를 완화하려면 연동에 대해 타임아웃을 지정하는 것이다. 타임아웃을 5초로 지정했을 때, 5초가 지난 뒤 사용자에게 시간 초과 에러를 응답하면서 서버가 여러 요청을 알맞게 처리할 수 있다. 사용자는 타임아웃으로 지정한 시간 뒤에 에러 화면을 보게 되지만 반응 없는 무한 대기보다는 에러 화면을 보는 것이 더 낫고 자원이 포화되어 서버 전체가 마비되는 것 보다도 훨씬 낫다.
2가지 타임아웃 : 연결 타임아웃, 읽기 타임아웃
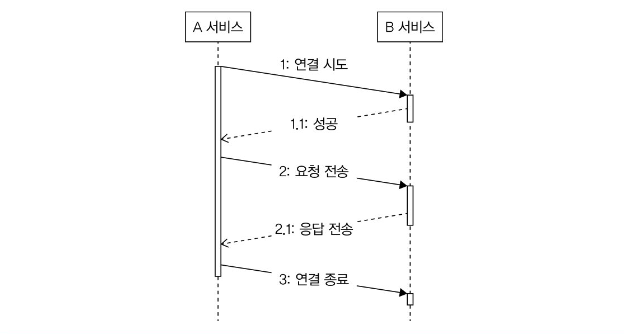
API 연동 통신 과정을 단순화해서 그림처럼 표현하면 연결, 요청, 응답, 종료 4단계를 거친다.
첫 단계는 네트워크 연결 시도 단계인데, 연결에는 당연히 물리적인 시간이 걸린다. 물론 속도가 빠르긴 하지만, 실제 네트워크 전송 속도는 빛보다 느리기 때문에 네트워크 상황이나 서버의 상태에 따라 연결에 오랜 시간이 걸릴 수 있다. 연결에 시간이 오래 걸리면 대기 시간도 함께 증가한다. 당연히 대기 시간이 무한정 길어지면 성능 문제가 발생하므로, 연결 타임아웃을 설정해 연결 대기 시간을 제한해야 한다.
일단 연결이 되면 요청을 전송하고 응답을 기다리게 된다. 이때 응답을 받기까지 시간이 오래 걸리면 앞서 말한 대기 시간 문제가 다시 발생한다. 따라서 읽기 타임아웃을 설정해서 응답 대기 시간을 제한해야 한다.
아래는 일반적인 타임아웃 시간이다.
- 연결 타임아웃: 3초 ~ 5초
- 읽기 타임아웃: 5초 ~ 30초
읽기 타임아웃이 다소 길게 느껴질 수 있다. 하지만 처음부터 너무 짧게 설정하면 타임아웃 에러가 자주 발생할 수 있기 때문에 처음에는 약간 길게 설정해놓고 조정해나가는게 더 좋다.
Tip: 소켓 타임아웃 vs 읽기 타임아웃
Apache HttpClient는 소켓 타임아웃을 설정하는데, 네트워크 패킷 단위를 기준으로 하므로 전체 응답 시간에 대한 타임아웃을 의미하지 않는다. 그래서 소켓 타임아웃을 5초로 지정해도 전체 응답 시간은 5초 이상 걸릴 수 있고, 만약 그래서 조금씩 패킷을 보낸다면 무한정 대기도 가능하다.
그런데 OkHttp는 읽기 타임아웃과는 별개로 호출 타임아웃을 설정할 수 있다. 호출 타임아웃은 요청 시작부터 응답까지의 전체 시간 기준으로 설정된다. 소켓 타임아웃을 5초로, 호출 타임아웃을 10초로 설정하면 패킷은 계속 수신되지만 전체 처리 시간이 오래 걸리는 경우에 타임아웃을 발생시킬 수 있다.
재시도 🔄
외부 연동에 실패했을 때 처리 방법 중 하나는 재시도를 하는 것이다. 네트워크 통신 과정에서 간헐적으로 연결에 실패하거나 일시적으로 응답이 느려지는 경우에는 재시도를 통해 실패 → 성공 전환이 가능하다.
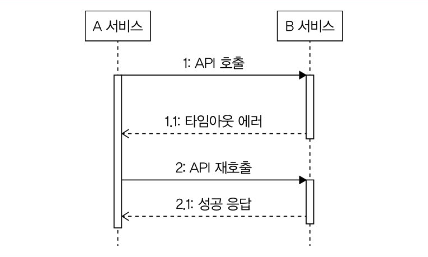
재시도 가능 조건
재시도를 통해 연동 실패를 줄일 수는 있지만, 항상 재시도를 할 수 있는 건 아니다. 연동 API를 다시 호출해도 되는 조건인지 확인해야 한다.
예를 들어 포인트 서비스가 제공하는 API를 호출해 포인트를 차감하는 상황을 생각하면, 포인트 차감 API를 호출해서 차감을 했는데 타임아웃과 같은 이유로 재시도를 하게 되면 포인트 차감이 두 번 발생한다.
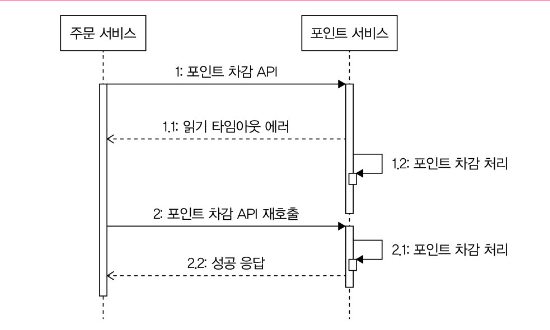
이런 식으로 차감이 두 번 된다? 그러면 니 서비스는 크~~~을 난다.
재시도를 해도 되는 조건은 아래 3가지로 정리할 수 있다.
- 단순 조회 기능
- 연결 타임아웃
- 멱등성(idempotent)을 가진 변경 기능
당연히 단순 조회 기능은 데이터에 문제를 주는게 아니기 때문에 일시적인 문제가 발생했을 때 다시 조회해서 정상적으로 처리될 가능성을 높일 수 있다.
연결 타임아웃도 마찬가지다. 연결 타임아웃이 발생했다는 것은 연동 서비스에 아직 연결되지 않은 상태라는 뜻이다. 연동 서비스가 요청을 제대로 처리를 안하고 있다는 것이여서, 순간적인 네트워크 문제였다면 재시도를 통해 연결에 성공할 가능성이 있다.
읽기 타임아웃은 재시도할 때 주의해야 한다. 이 경우는 이미 연동 서비스가 요청을 처리하고 있는 중이기 때문이다. 만약 위 사례처럼 재시도를 해서 포인트를 중복 차감하면 데이터 문제가 생길 수 있다.
그래서, 상태 변경을 하는 연동 API를 재시도할 때는 멱등성을 고려해야 한다. 멱등성이란 “연산을 여러 번 적용해도 결과가 달라지지 않는 성질”을 말한다.
아직 좋아요를 하기 전이면
- 좋아요 정보를 추가한다
- 콘텐츠의 좋아요 수를 증가시킨다
- 200 상태 코드를 응답한다
이미 좋아요를 했다면 아무 동작을 하지 않고 200 상태 코드를 응답하기 때문에, 한 사용자가 동일한 콘텐츠에 대해 여러 번 좋아요 API를 실행해도 좋아요는 한 번만 반영된다. 좋아요 API를 실행하는 동안 읽기 타임아웃이 발생해서 재시도해도 데이터는 이상 상태를 갖지 않기 때문에 알빠 아니다.
같은 API라도 실패 원인에 따라 재시도 여부를 결정해야 한다. 검증 오류가 발생했다면 재시도를 해도 동일하게 실패할 가능성이 높다. 예를 들어, 좋아요 API를 호출할 때 콘텐츠 ID를 빈 값으로 전달했다면 입력 자체가 잘못 들어와서 400 에러를 응답할텐데, 당연히 같은 이유로 실패를 하게 될 것이다.
재시도 횟수와 간격
재시도에는 다음 2가지를 결정해야 한다
- 재시도 횟수
- 재시도 간격
재시도 횟수를 결정한다. 당연히 무한정 할 수는 없다. 재시도 횟수만큼 응답 시간도 함께 증가하기 때문이다. 대부분 1~2회 정도의 재시도가 적당하다. 2번 재시도를 하면 총 3번 시도한 것인데, 모두 실패했다면 간헐적인 오류보다는 다른 근본적인 문제가 있을 수 있기 때문에 다시 재시도해도 실패할 확률이 높다.
재시도 간격도 중요하다. 네트워크 연결 상태가 6초간 좋지 않은 상황을 가정해보자. 연동 API를 호출했을 때 3초 후 연결 타임아웃이 발생하게 된다. 이때 바로 재시도하면 같은 네트워크 문제로 인해 또 문제가 발생한다. 근데 3초 간격을 두고 재시도 한다? 그러면 문제가 해결될 가능성이 높다.
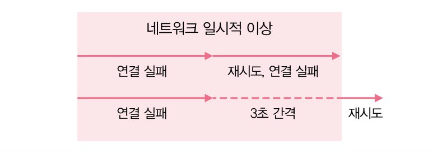
재시도할 때는 재시도 간격을 첫 번째 1초 → 두 번째 2초 이런 식으로 점진적으로 늘리면 연동 서버에 가해지는 부하를 완화할 수 있다.
재시도 폭풍(retry storm) 안티패턴
재시도를 통해 성공 가능성을 높일 수 있지만, 반대로 연동 서비스에 더 큰 부하를 줄 수 있다. 연동 서비스가 성능이 느려져서 읽기 타임아웃이 발생한 상황인데 계속 재시도로 요청을 보낸다? → 당연히 연동 서비스에 부하가 더해지고, 연동 서비스 보고 죽으라는 소리다.
동시 요청 제한 🚦
연동 서비스가 한번에 처리할 수 있는 요청이 100개인데, 요청 300개를 보낸다면?
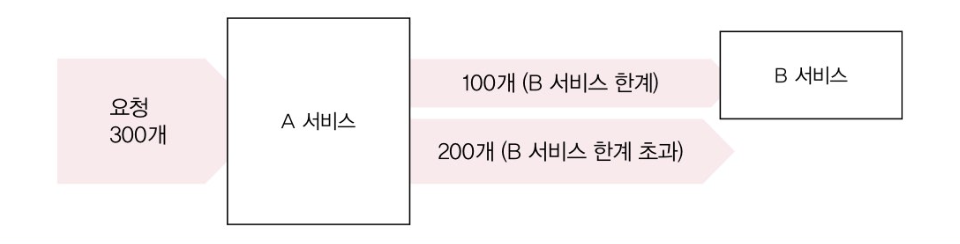
당연히, 연동 서비스의 최대 TPS를 넘었기 때문에 연동 서비스에 부하가 가해지고 서비스가 느려지기 시작한다. 그러면 이걸 완화할 수 있는 방법은? → 당연히 요청을 일정 수준 이상으로 보내지 않는 것이다.
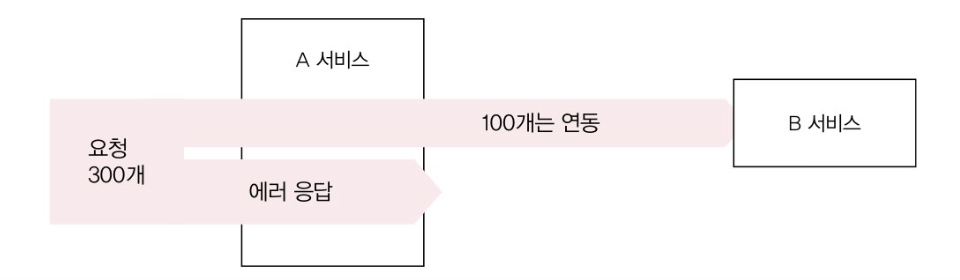
음, 나는 일종의 Rate Limiter라고 봤는데 잘 생각을 해보면 보내는 쪽 서비스에서 차단을 하는 것이여서 이걸 Rate Limiter라고 하는게 맞나? 싶다. 어쨌든 A 서비스에서 503(Service Unavailable) HTTP 상태 코드를 보내서 서버가 더 이상의 요청을 받을 수 없음을 알리며 에러를 반환해야 한다.

서킷 브레이커 ⚡
연동 서비스에 과부하가 발생해 혹은 알 수 없는 이유로 제대로 응답을 주지 못하고 있는 상황이라고 하자. 근데, 이걸 차단을 안하고 계속 요청을 보낸다? 당연히 제대로 안된다. 또한 읽기 타임아웃 시간을 기다리느라 응답 시간도 길어진다.

위 그림처럼 서비스 B가 제대로 된 요청을 처리하지 못할 때는, A 서비스가 요청을 보내지 않고 바로 에러를 응답하는 것이 더 낫다. 이렇게 하면 B 서비스가 A 서비스에 주는 영향(응답 시간 증가, 처리량 감소 등)을 줄일 수 있다. 당연히 이전에 말했던 것처럼 사용자 입장에서도 그 편이 더 낫다.
서킷 브레이커가 이러한 역할을 한다
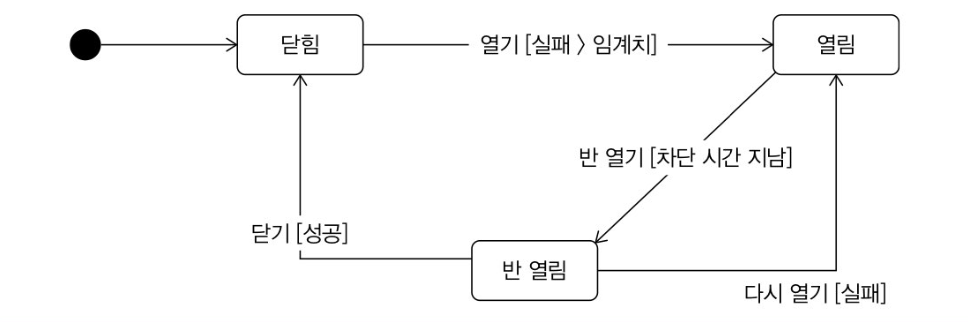
서킷 브레이커는 닫힘, 열림, 반 열림 상태로 크게 3가지가 있다. 최초에는 닫힘 상태로 시작을 한다. 닫힘 상태일 때는 모든 요청을 연동 서비스에 전달한다. 오류가 발생하기 시작하면 threshold(임계치)에 도달했는 지 확인한다. 실패 건수가 임계치를 넘었다면 열림 상태로 전환한다. 서킷 브레이커는 상태 감지로 슬라이딩 윈도우를 기본적으로 사용하며, 보통 임계치는 아래 두가지 케이스가 있다.
- 개수 기반(COUNT_BASED)
- 시간 기반(TIME_BASED)
열림 상태면 연동 요청을 보내지 않고 바로 에러를 응답한다. (열림 상태는 지정된 시간 동안 유지)
시간이 지나면 반 열림 상태로 전환되며, 반 열림 상태가 되면 일부 요청에 한해 연동을 시도한다. 일정 개수 또는 일정 시간 동안 반 열림 상태를 유지하며, 이 기간동안 성공한다? 그러면 다시 닫힘 상태로 복구
Spring Boot에서 서킷 브레이커 구현하기
알아봤을 때 일반적으로 스프링에서 서킷 브레이커를 구현하려면 Resilience4j 라이브러리를 주로 사용하여 서킷 브레이커를 구현한다고 한다. 의존성을 추가하고, application.yml에 세부사항을 설정하면 된다. 아마 따로 Config을 만들어서 써도 될거다.
1
2
3
4
5
6
7
8
9
10
resilience4j:
circuitbreaker:
configs:
default:
slidingWindowSize: 10
failureRateThreshold: 50
waitDurationInOpenState: 10s
instances:
external-service:
baseConfig: default
reference: Circuit Breaker
외부 연동과 DB 연동 🔄
이게 외부 연동을 할 때 고민 포인트다. 이제 외부 연동을 할 때, DB 연동도 할텐데 오류 발생 시 트랜잭션 처리를 어떻게 할 것이냐. 이걸 잘 고민해야 한다.
당연히 흔히 발생하는 케이스는 아래 두 가지가 있다.
- 외부 연동에 실패했을 때, 트랜잭션 롤백
- 외부 연동은 성공했는데 DB 쪽에서 실패해서 롤백
외부 연동에 실패했을 때, 트랜잭션 롤백
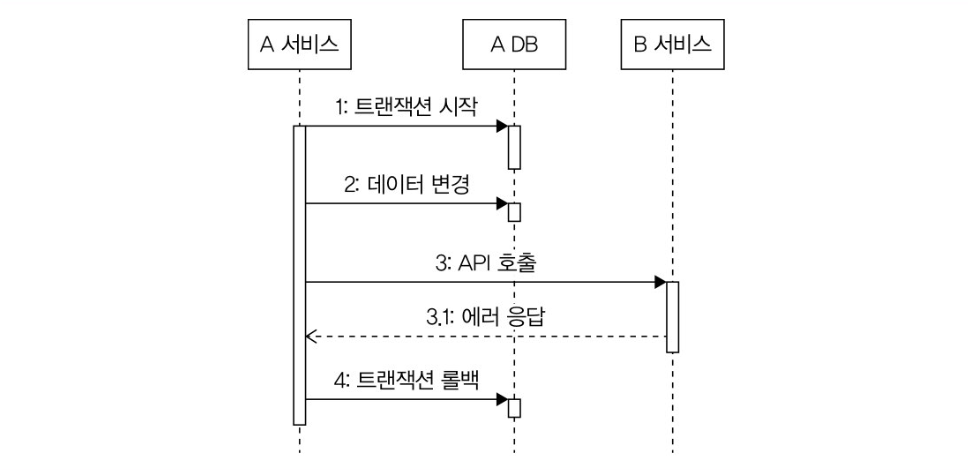
트랜잭션 범위 안에서 외부 연동에 실패했을 때는? → 트랜잭션 롤백이 된다. 당연히 이 경우에는 변경된 데이터가 DB에 남지 않는다. 단순하지만 간단한 방법이다.
근데 이 경우에 읽기 타임아웃에 의한 실패로 인해 트랜잭션이 롤백된다면 외부 서비스가 실제론 성공했을 가능성을 염두해둬야 한다. 외부 연동 서비스가 멱등하다면 신경을 안써도 될 거 같다.
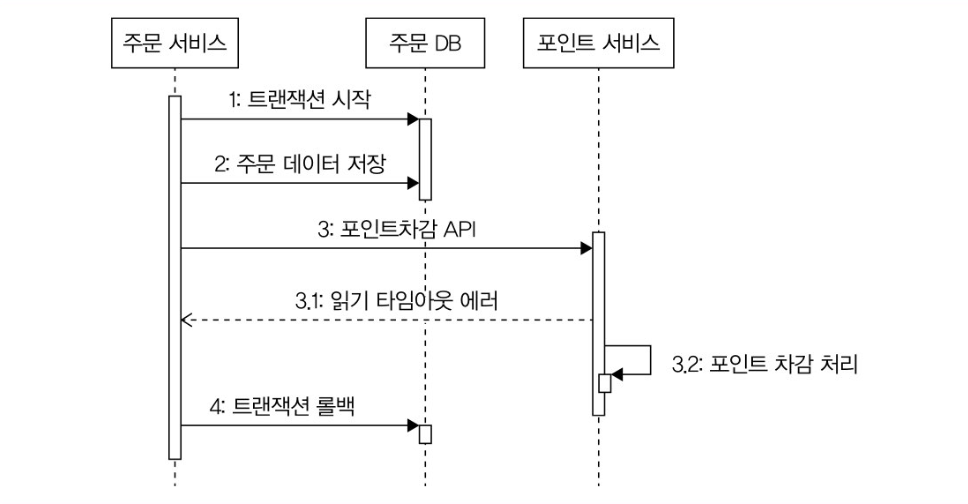
위와 같은 상황에서 읽기 타임아웃으로 인해 롤백을 했다면 아래 두 가지 방식을 검토해야한다.
- 일정 주기로 확인해서 데이터 보정하기
- 성공 확인 API 호출하기
일정 주기로 확인해서 데이터를 보정하는 방법은 스케줄링을 활용해서 데이터 일치 여부를 확인해서 보정하는 방법이다. 수동 혹은 자동으로 보정해주면 된다.
성공 확인 API를 호출하는 방법은 읽기 타임아웃 발생한 경우, 일정 시간 후에 이전 호출이 실제로 성공했는지 확인할 수 있는 API를 호출한다.(아마 이걸 확인할 수 있는 조회용 API를 쓰는 듯 싶다). 이때 성공 응답이 온다? 그러면 트랜잭션을 지속하고, 실패 응답이 오면 트랜잭션을 롤백한다.
이 방식의 변형으로 취소 API를 호출하는 방법도 있다. 읽기 타임아웃이 발생한 뒤 일정 시간 후에 취소 API를 호출하는 것이다. 연동 서비스는 취소할 대상이 있으면? → 취소 처리 없으면 어차피 동작 안하고 성공 응답만 반환한다(음 성공 응답이 맞는 지는 잘 모르겠음). 이 경우에는 연동 처리를 취소했기 때문에 트랜잭션을 롤백하면 된다고 한다.
근데 여기서 궁금한건 일정 시간 후에 이전 호출에 대한 성공, 실패 여부를 확인하는 API를 호출하는건데, 트랜잭션을 지속하거나 롤백한다는 건 트랜잭션을 계속 열어둔다는 의미다. 근데 이러면 그 일정 시간동안 커넥션을 잡아먹고 있는게 아닌가? 하는 생각이 듦
근데 성공, 실패 API는 연동 서비스가 제공을 할 때 쓸 수 있는거고, 이 API들을 호출할 때도 읽기 타임아웃이 발생할 수 있어서 일관성이 엄청 중요하다? → 그러면 정기적으로 데이터 일치를 확인하는 편이 낫다.
외부 연동은 성공했는데 DB 연동에 실패해서 트랜잭션을 롤백
외부 연동은 성공했지만, DB 연동에 실패해서 롤백되는 경우에는 취소 API를 호출해서 외부 연동을 이전 상태로 되돌리는 것이 필요하다. DB 연동에 실패했기 때문에, 이 경우에는 성공 확인 API를 호출해도 의미가 없다.
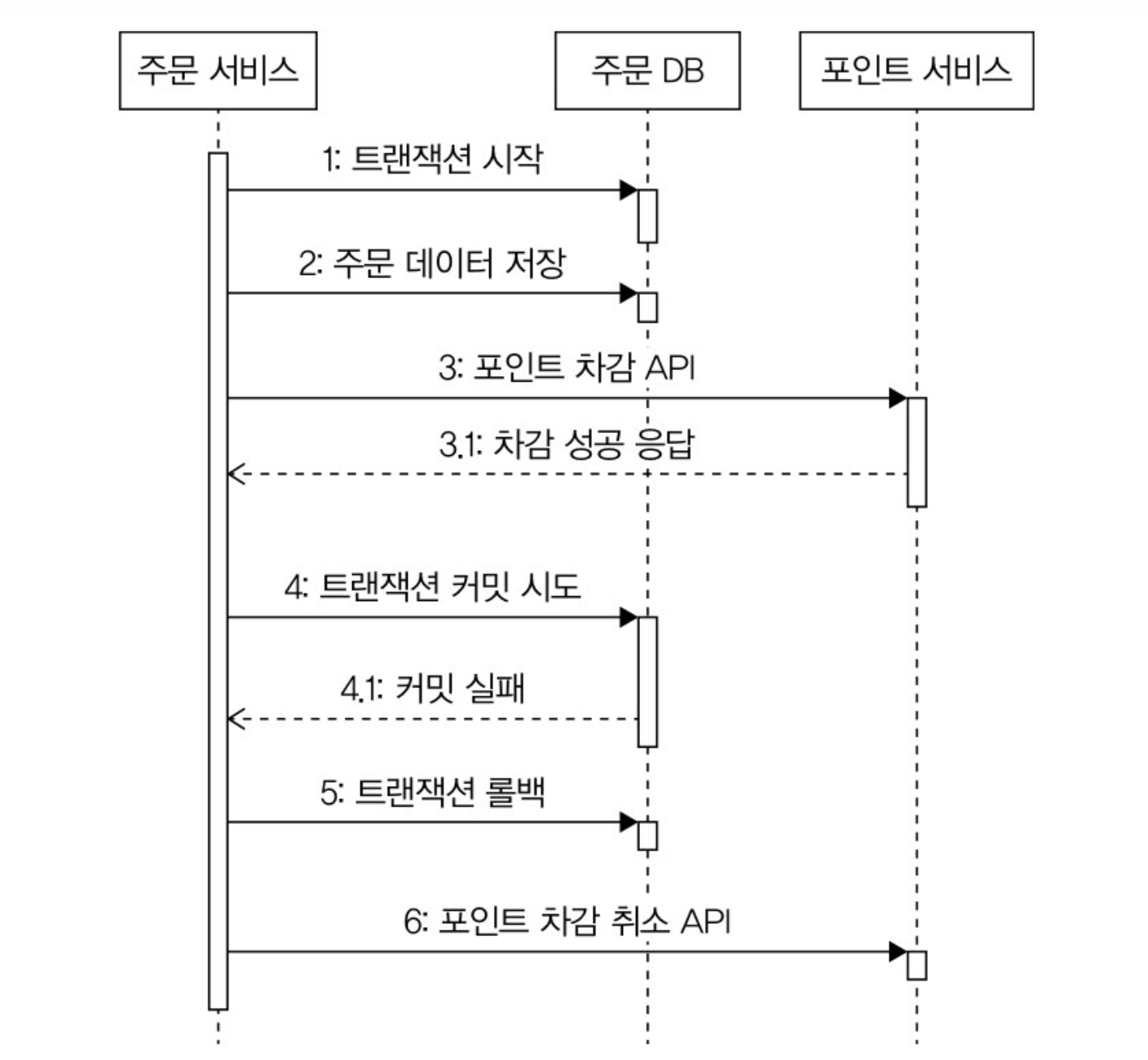
이것도 취소 API가 없거나 취소에 실패할 수도 있어서 데이터 일관성이 중요하면 일정 주기로 데이터가 맞는지 비교하는 프로세스를 갖춰야 한다.
외부 연동이 느려질 때 DB 커넥션 풀 문제
DB 트랜잭션 범위 안에서 외부 연동을 할 때, 외부 연동이 느려지면 커넥션 풀 부족 현상이 발생할 수 있다. 예를 들어, 기능 실행에 5초가 걸리는 상황이 있다고 치자.
- 커넥션 풀에서 커넥션을 가져온다.
- 0.1초가 걸리는 DB 쿼리를 실행한다.
- 외부 연동 API(4.8초 정도 실행 가정)를 호출한다.
- 0.1초가 걸리는 DB 쿼리를 실행한다.
- 커넥션을 풀에 반환한다.
이 시나리오에서 외부 연동을 제외하면, 실제 DB 커넥션이 사용되는 시간이 0.2초에 불과하다. 근데 외부 연동이 4.8초가 걸리면서 커넥션이 5초가 걸린다. 즉, DB 쿼리는 안 날리는 동안 커넥션은 점유된 상태라는 거다.
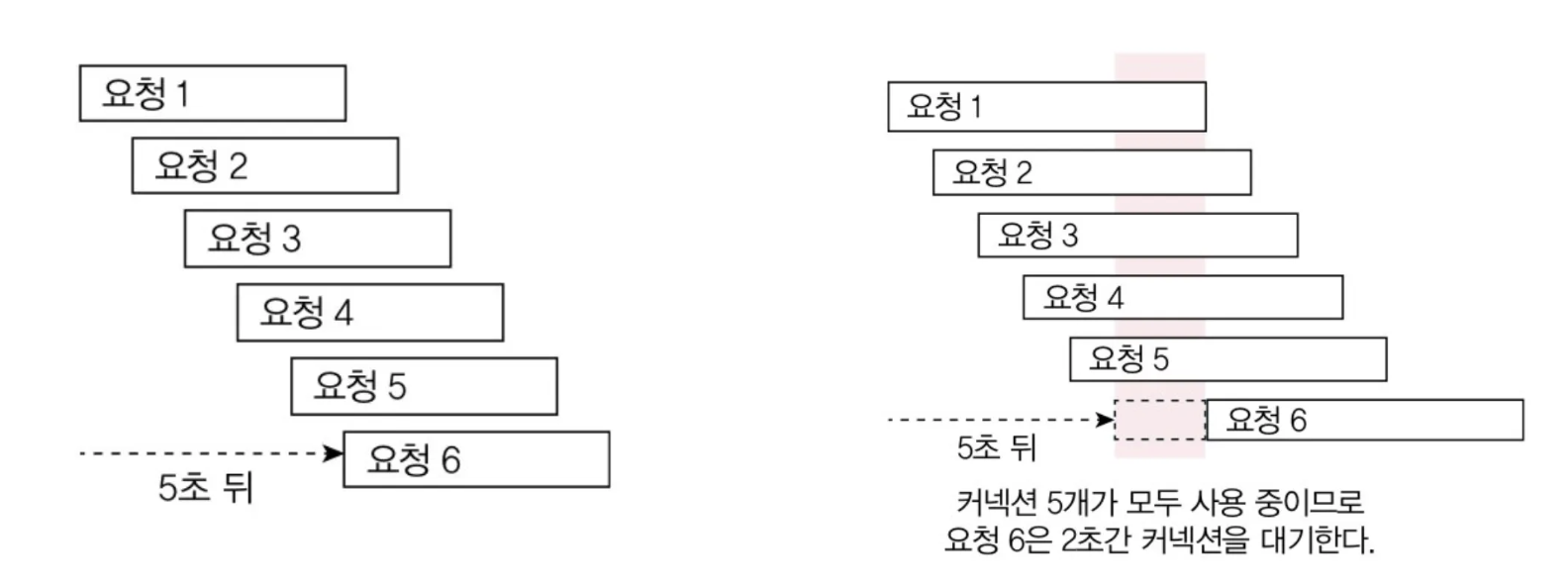
책의 자세한 가정은 생략하고 그냥 생각해봐도 당연히 문제가 있다.
- 외부 연동 시간이 늘어날 수 있는거고
- 커넥션 풀은 무한대가 아니기 때문에 트래픽이 많으면 포화될 수 있다.
이제 그래서 DB 연동과 무관하게 외부 연동을 실행할 수 있다면, DB 커넥션을 사용하기 전이나 후에 외부 연동을 시도하는 방안도 고려해볼 수 있다(트랜잭션을 작게 나누거나 비동기 처리를 하는 걸 의미하는 것 같다). 이렇게 하면 외부 연동이 길어지더라도 DB 커넥션 풀이 포화되는 상황을 방지할 수 있다. 당연히, 트랜잭션 범위 밖에서 실행되기 때문에 커밋 이후 외부 연동에 실패하면 롤백이 불가능하다. → 후처리를 고려해야한다는 뜻이다. ex) 보상 트랜잭션, 데이터 후보정
HTTP 커넥션 풀 🌐
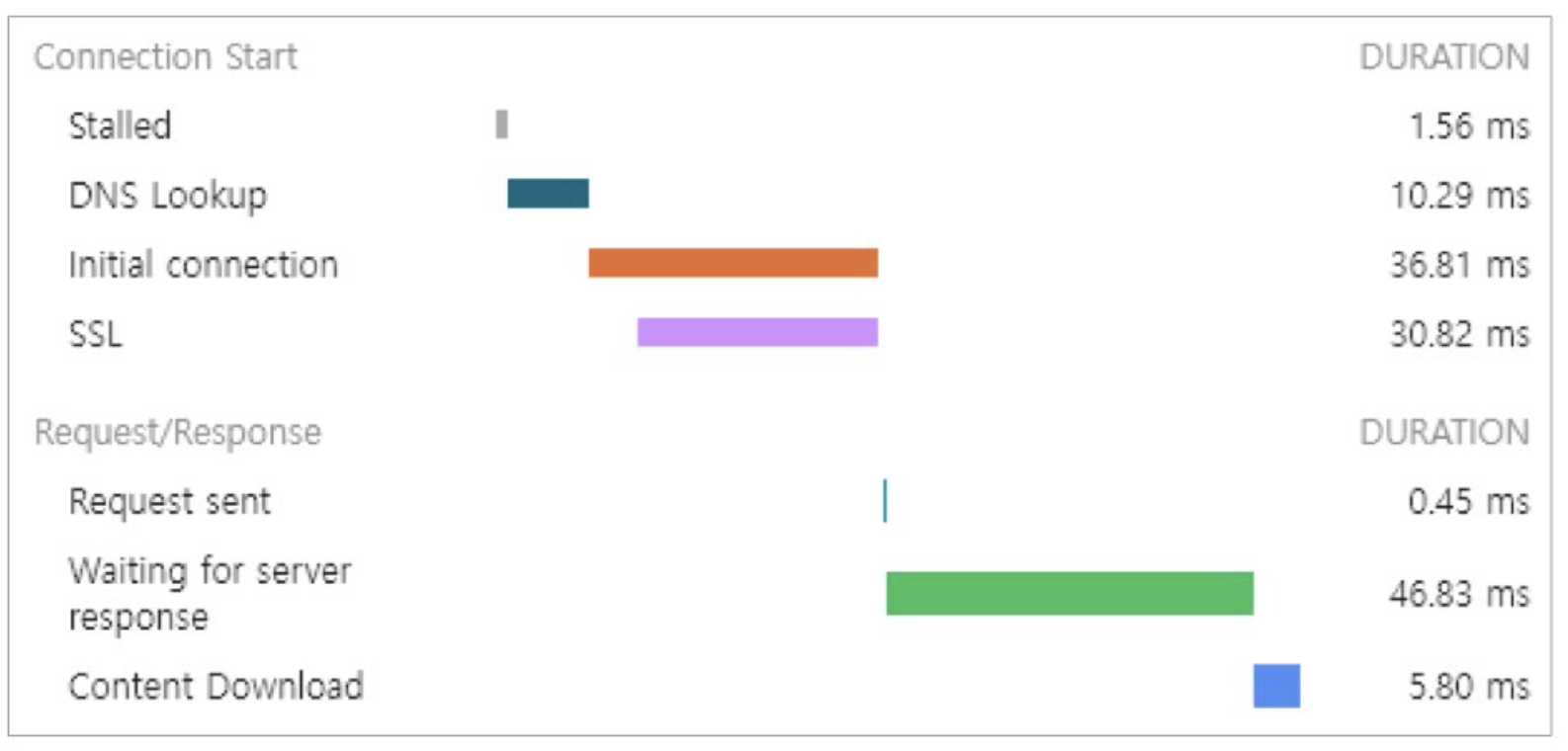
요 사진은 크롬 브라우저의 개발자 도구로 인터넷 URL의 처리 시간을 분석한 것이다. 콘텐츠 다운로드에 걸린 전체 시간이 0.1초인데, 서버 연결이 약 0.047초로 약 47%를 차지하고 있다. 이 말은, 전체 처리 시간에서 연결 시간이 차지하는 비중이 크다는 얘기다.
DB 커넥션 풀이 DB 연결에 걸리는 시간을 줄여 성능을 높이는 것처럼 HTTP 연결도 커넥션 풀을 사용하면 연결 시간을 줄일 수 있어 당연히 응답 속도 향상에 도움이 된다.
HTTP 커넥션 풀을 사용할 때는 다음 3가지를 고려해야 한다
- 커넥션 풀 사이즈
- 풀에서 HTTP 커넥션을 가져올 때까지 대기하는 시간
- HTTP 커넥션을 유지할 시간(keep alive)
당연히 풀 사이즈는 중요한데, 이건 연동 서비스의 성능에 따라 결정해야 한다. 우리가 DB 커넥션 풀을 쓸 때 DB CPU 사용량을 확인해서 결정해야 하듯이 얘도 연동 서비스의 성능을 고려하는 거다.
두 번째는 대기 시간이다. HTTP 커넥션 풀의 크기가 10이라면 동시에 11개의 외부 연동 요청이 들어올 경우 10개는 커넥션을 확보해서 실행을 하고, 남은 한 개는 대기한다. 당연히 대기 시간이 길어지면 응답 시간이 늘어난다는 얘기기 때문에 대기 시간을 수 초 이내로 짧게 설정하는게 좋다(경험상 1~5초란다). 너무 짧게하면 일시적인 트래픽 증가에도 커넥션을 못 구해서 에러가 발생하고 너무 길게하면 당연히 연동 서버가 느려졌을 때 전체 응답 시간이 늘어나는 문제가 발생할 수 있다.
세 번째는 커넥션 유지 시간이다. 커넥션은 무한정 유지되지 않는다. 연동 서비스가 일정 시간 동안만 커넥션 유지한 뒤 끊는 경우도 있다(DB도 마찬가지다). 끊어진 커넥션을 사용하면 에러가 뜨니까 연동 서비스에 맞춰서 적절하게 유지 시간을 설정해야 한다. HTTP/1.1에서는 서버가 Keep-Alive 헤더로 연결 유지 시간을 지정하는데, 이 시간이 지나면 서버가 연결을 끊으니까 클라이언트의 커넥션 풀도 이 값보다 더 오래 커넥션을 유지하면 안된다.
연동 서비스 이중화 🔄
서비스가 대량 트래픽을 처리할 만큼 커졌다? 그러면 연동 서비스의 이중화를 고려해야 한다. 당연히 하나만 쓴다는 건 SPOF가 있다는 거다. 그래서 이중화를 해서 한 곳에 장애가 발생해도 대응을 해야한다.
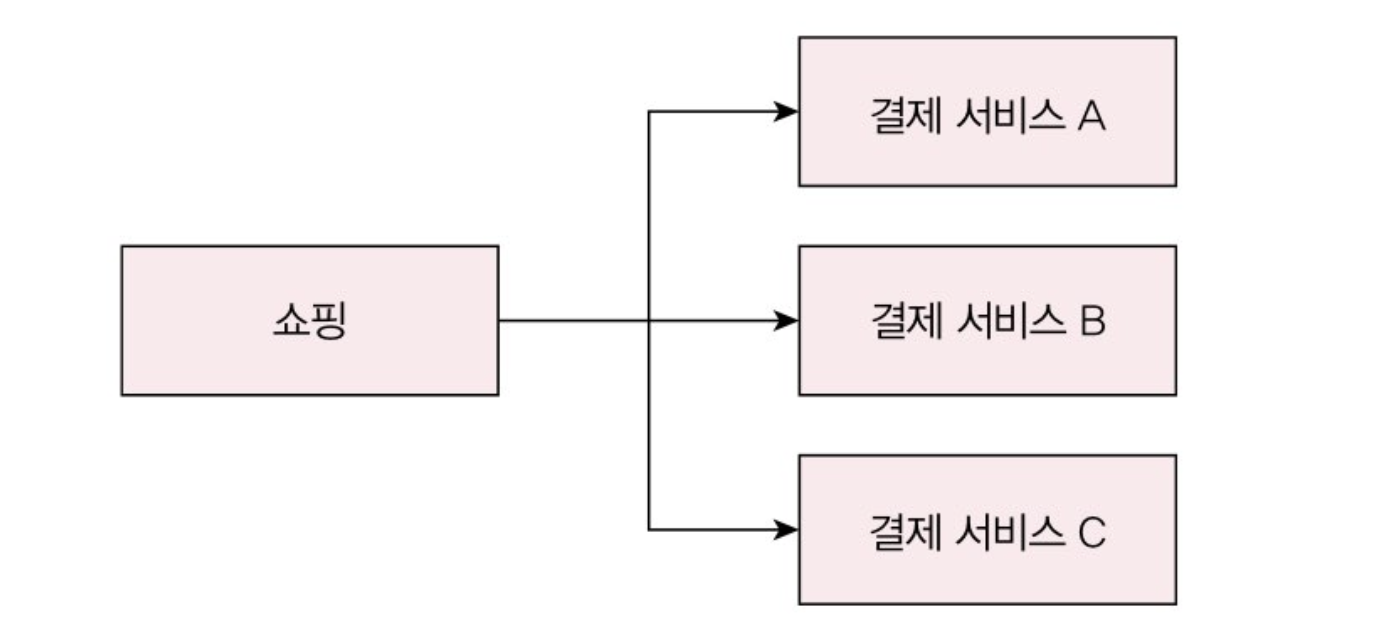
당연히 개발, 유지 비용이 증가하겠지만 필요하면 해야지 어쩌냐? 그래서 두 가지를 고려해야 한다.
- 해당 기능이 서비스의 핵심인지
- 이중화 비용이 감당 가능한 수준인지
그니까 뭔 얘기냐 굳이 그렇게까지 중요하지 않으면 돈 쓰지 말란 얘기다.
결론 🎯
외부 연동은 현대 서비스에서 필수적이지만, 그만큼 신경 써야 할 부분도 많다. 타임아웃, 재시도, 서킷 브레이커, 커넥션 풀 등 다양한 기법을 통해 안정적인 외부 연동을 구현할 수 있다.
하지만 가장 중요한 것은 비즈니스 요구사항과 비용을 고려한 적절한 선택이다. 모든 것을 완벽하게 구현하려고 하면 오히려 복잡성만 증가할 수 있으니, 핵심 기능부터 차근차근 적용해나가는 것이 좋겠다.