느려진 서비스, 어디부터 봐야 할까 [주니어 백엔드 실무지식]
느려진 서비스, 어디부터 봐야 할까 🚀
서비스가 느려졌을 때 가장 먼저 확인해야 할 지표들과 성능 개선 방법에 대해 알아보자.
처리량과 응답 시간
통상적으로 응답시간이 10초 이상? → 성능이 나쁘다
성능 저하가 있으면 가장 눈에 띄는 현상은 결과가 늦게 표시되는 것이다
다양한 지표 중 응답 시간과 처리량이 서버 성능과 관련된 주요 지표다
응답 시간
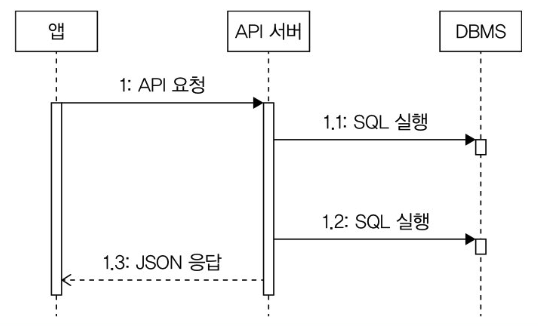
- TTFB(Time to First Byte): 응답데이터 중 첫번째 바이트가 도착할때까지 걸린시간
- TTLB (Time to Last Byte): 응답 데이터의 마지막 바이트가 도착할 때까지 걸린 시간
→ 응답 데이터의 크기에 따라 차이가 커질 수 있으므로 데이터 특성과 네트워크 환경을 고려해서 적절한 지표를 확인해야 한다(단위는 밀리세컨드 ms)
응답시간이 사업에 주는 영향 (부록)
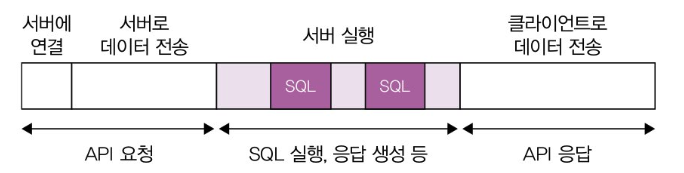
응답시간 구성 요소:
- 로직수행(i, for등)
- DB연동(SQL실행)
- 외부API연동
- 응답데이터생성(전송)
전체처리시간: 348ms
- API 연동1(외부네트워크): 186ms(53%)
- API연동2(내부네트워크): 44ms(13%)
- DB연동(SQL실행6회): 101ms(29%)
- 로직수행: 17ms(5%)
위의 지표로 미뤄보아 응답시간을 줄일때 DB연동과 API 연동시간에 집중하면 도움이 될 것이다.
처리량
단위 시간당 시스템이 처리하는 작업량 → 주로 TPS(Transaction Per Second) RPS(Request Per Second)
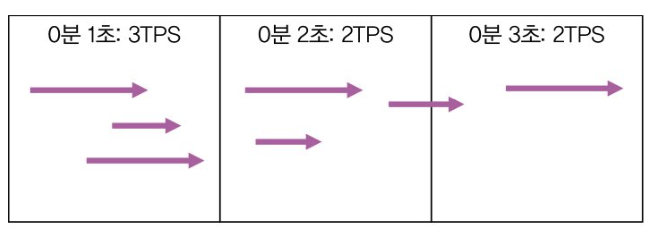
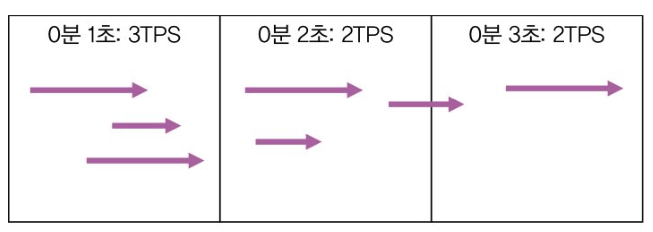
- 1 구간(0분 1초): 완료된 요청이 3개이므로 TPS = 3
- 2 구간(0분 2초): 완료된 요청이 2개이므로 TPS = 2
- 3 구간(0분 3초): 완료된 요청이 2개이므로 TPS = 2
최대 TPS: 시스템이 처리할 수 있는 최대 요청 수
ex) 서버가 한번에 5개의 요청을 처리할 수 있다고 가정하자. 이때 요청 당 처리시간이 1초라면 최대 TPS = 5
→ 초과한건 나중에 처리
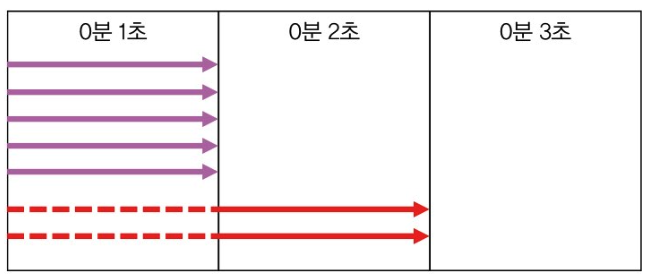
최대 TPS가 5인 서버에 동시 요청이 7개가 들어왔을 때,
- 5개는 잘 처리
- 나머지 2개는 앞에꺼가 끝나야 처리
- 2명의 사용자 입장에서는 2초로 느껴지고 사용자 이탈로 이어질 수 있음
해결 방법:
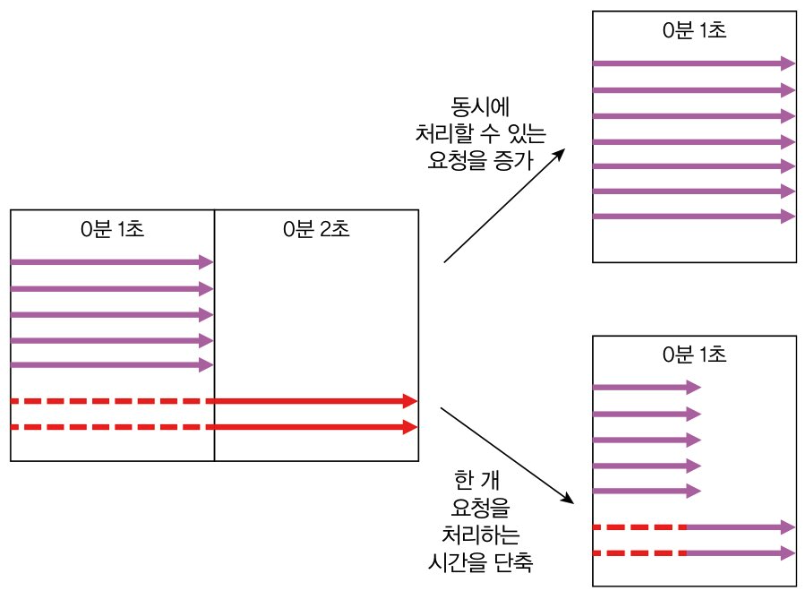
- 서버가 동시에 처리할 수 있는 요청 수를 늘려 대기시간 줄이기
- 처리시간 자체를 줄여 대기시간 줄이기
성능 개선을 하고 싶으면, 먼저 현재 서버의 TPS와 응답 시간을 알아야하고 이는 모니터링을 해야한다는 말이다.
서버 성능 개선 기초
병목 지점
사용자가 늘고 데이터가 쌓이고 트래픽이 늘면 성능 문제가 발생한다
전형적인 증상:
- 순간적으로 모든 사용자 요청에 대한 응답시간이 심각하게 느려진다. 10초 이상 걸리는 요청이 늘어나고 다수의 요청에서 연결시간 초과와 같은 오류가 발생한다.
- 서버를 재시작하면 잠시 괜찮다가 다시 응답시간이 느려지는 현상이 반복된다.
- 트래픽이 줄어들 때까지 심각한 상황이 계속된다.
트래픽이 증가하면서 성능 문제가 발생하는 주된 이유는 시스템의 최대 TPS를 초과하는 트래픽이 유입되기 때문이다. 즉 시스템이 제공할 수 있는 최대 TPS를 늘려야 한다.
성능 문제가 발생하는 지점을 찾는 법?
처리 시간이 오래 걸리는 작업을 식별 → 성능 문제는 응답 시간이 길어지면서 발생하는 경우가 많기 때문
처리 시간이 길어진다 → 서버의 스레드와 커넥션이 잡아먹힌다 → 최대 TPS가 낮아진다
당연히 앞서 말했듯이 모니터링으로 잡는거다. 근데, 경험상 DB나 외부 API 연동 과정에서 발생한다.
수직적 확장(돈찍누)과 수평적 확장
급한 불을 끄고 싶다? → 돈찍누로 서버 자원을 올려라(클라우드일수록 쉽다)
DB던 서버든 돈찍누로 올리면 문제 원인을 찾아 해결할 시간을 벌 수 있다
근데 평생 할수는 없잖아?
→ 수평적인 확장이 필요하다
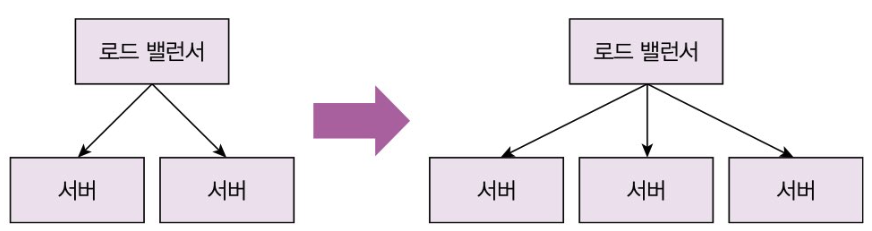
수평적 확장 방법
TPS를 높이겠다고 무턱대고 서버를 올리면 안된다. 실제 병목 지점이 어디인지 파악해야한다.
ex) DB에서 성능 저하가 발생했는데 서버를 늘리면 DB에 오히려 부하를 더한다.(외부 API도 마찬가지)
DB 커넥션 풀
DB를 사용하려면 다음 3단계를 거친다
- DB에 연결한다
- 쿼리를 실행한다
- 사용이 끝나면 연결을 끊는다.
근데 이 네트워크 연결 작업을 매번 새로 한다면? → 시간도 소요되고, 서버 자원도 더 많이 써야한다
그러면 당연히 처리량은 떨어질 것이다.
그래서, 커넥션 풀 을 사용한다
DB에 연결된 커넥션을 미리 생성해서 보관하고 사용하는 것이다.(Http 커넥션 풀도 있다)
Springboot는 HikariCP를 커넥션 풀로 사용한다.
커넥션 풀의 주요 설정:
- 커넥션 풀 크기(또는 최소 크기, 최대 크기)
- 풀에 커넥션이 없을 때 커넥션을 구할 때까지 대기할 시간
- 커넥션의 유지 시간(최대 유휴 시간, 최대 유지 시간)
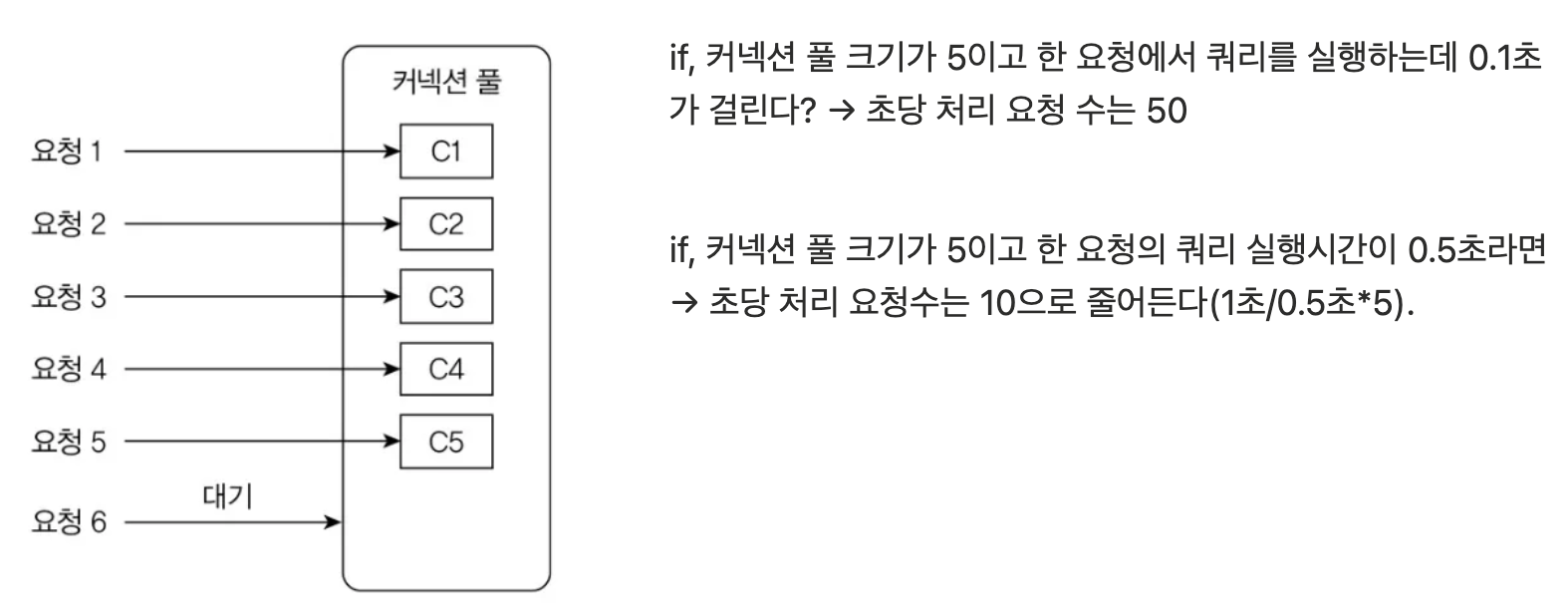
이 상태에서 동시에 50개의 요청이 들어오면 모든 요청을 처리하는데 5초가 걸린다.
어떤 요청은 0.5초만에 실행이 끝나지만, 다른 요청은 커넥션을 구하기 위해 4.5초를 기다렸다가 쿼리를 실행
이때는 응답시간을 줄이기 위해 커넥션 풀 크기를 50으로 늘려 모든 요청을 0.5초 이내에 처리할 수 있다.
일반적으로 트래픽은 증감 패턴을 보이기 때문에, 최대, 최소 커넥션 풀 사이즈를 알맞게 조절하면 된다.
단, DB 상태를 보고 CPU 사용률이 80%가 넘어가고 이러는데 커넥션 풀 사이즈를 늘린다?
그냥 DB보고 죽으라는거다.
커넥션 대기 시간
커넥션을 얻기 위해 대기하는 시간 → 대부분은 이런 최대 시간이 정해져 있음(HikariCP는 기본 30초)
많은 경우, 적당히 짧게 조절을 해서 빨리 에러 응답을 사용자에게 보여주는게 낫다.
이건 자세한 설명은 생략한다.
여튼, 대기 중인 요청수가 계속 증가한다는건 서버가 동시에 처리해야하는 요청이 증가한다는거고 당연히 서버 부하가 커지게 된다. 그래서 차라리 짧게 타임아웃을 걸고 빨리 에러 응답을 하는게 사용자한테도 우리한테도 좋다.
최대 유휴 시간, 유효성 검사, 최대 유지 시간
새벽 시간은 군대에서도 다 자는 시간이다. 서버에서도 요청이 별로 없다. → 풀에 있는 커넥션도 사용되지 않는다 근데? 안쓰는데 연결은 길어진다? → 연결이 끊길수도 있다.(MySQL은 자체 기능 제공)
예를 들어, DB가 1시간 동안 상호작용 없는 클라이언트와의 연결을 끊는다고 가정하자. 그러면 새벽 시간에 모든 커넥션이 끊긴다. 그러면 이걸 쓰면? → 당연히 에러가 발생한다.
그래서 아래 2가지 기능을 제공한다
- 최대 유휴 시간 지정
- 유효성 검사
최대 유휴 시간은 사용되지 않는 커넥션을 풀에 유지할 수 있는 시간 요걸 DB에 설정된 비활성화 시간보다 짧게 설정하면 DB가 연결을 끊기 전에 해당 커넥션을 풀에서 없앨 수 있다.
유효성 검사는 커넥션이 정상적인지 상태 점검을 확인하는 절차 커넥션 풀의 구현 방식에 따라 커넥션을 풀에서 가져올 때 검사를 하거나, 주기적으로 검사할 수 있다.
이러한 과정으로 검사를 해서 이상한 애들을 풀에서 제거할 수 있다.
일부는 유효성 검사를 위해 실제 쿼리를 실행하기도 한다. 간단한걸로 날려서 (SELECT 1;)
커넥션 풀이 제공하는 또다른 기능은 유지 시간인데, 이건 말 안해도 알지? 걸어 놓은만큼 유지되는거
서버 캐시
DB 서버를 확장하지 않고 응답 시간과 처리량 개선을 하고 싶다? → 캐시는 좋은 대안이다.
Key, Value로 저장하는 Map 형태의 데이터 저장소이고 당연히 디스크가 아닌 메모리를 사용하는거다.
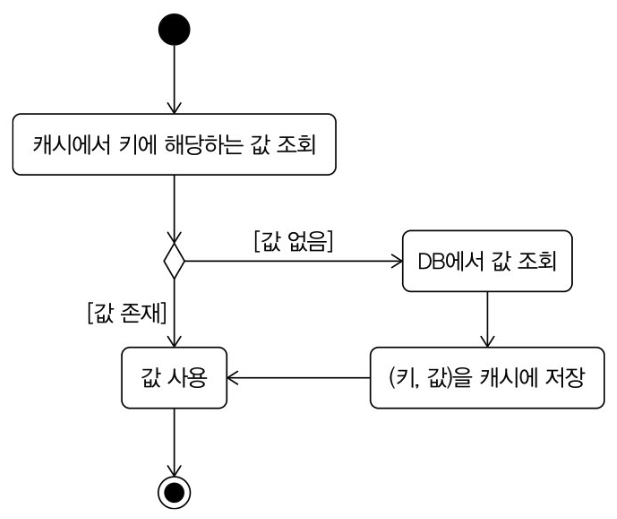
요런 식으로 캐시를 사용하면 먼저 캐시에서 조회를 해서 없으면 DB 조회를 하는 방식으로 DB 부하, 응답 시간을 줄일 수 있다. DB 뿐만 아니라 복잡한 계산 결과나 외부 API 연동 결과도 캐시에 저장을 해서 성능 개선이 가능
적중률과 삭제 규칙
적중률(hit rate): 캐시에 존재한 건수/ 캐시에서 조회를 시도한 건수
그니까 쉽게 말해 얼마나 때려 맞췄냐 이거지 → 당연히 잘 맞출수록 성능 개선에 도움이 된다
적중률을 높이는 방법
최대한 많은 데이터를 캐시에 저장하는 거 → 근데 당연히 한계가 있지 그래서 가득차면 삭제를 해야하고 삭제에는 규칙이 있다.
- LRU: 가장 오래전에 사용된 놈 죽이기
- LFU: 가장 적게 사용된 놈 죽이기
- FIFO: 먼저 들어온 놈(늙은 놈) 죽이기
많은 서비스에서 오래된 데이터보다 최신 데이터를 사용한다. 여기에 TTL 설정으로 오래된 놈들을 날리면서 효율적으로 관리해야 캐시를 잘 쓸 수 있다.
Redis Eviction 정책 (부록)
레디스는 디폴트가 삭제를 하는게 아니고 에러를 반환함.
그래서 적당한 eviction 정책을 사용을 해서 제거해야 함.
- noeviction
- 기본값(Default).
- 메모리가 꽉 차면 더 이상 쓰기 작업(SET, LPUSH 등)이 실패하고 에러를 반환.
- 기존 키는 삭제되지 않음.
- allkeys-lru
- 모든 키에서 가장 오랫동안 사용되지 않은 키(Least Recently Used, LRU)를 제거.
- volatile-lru
- TTL(만료 시간이 설정된) 키 중에서 LRU 기준으로 제거.
- allkeys-random
- 모든 키 중 무작위로 제거.
- volatile-random
- TTL이 설정된 키 중 무작위로 제거.
- volatile-ttl
- TTL이 설정된 키 중 남은 TTL이 가장 짧은 것을 제거.
- allkeys-lfu (Redis 4.0 이후)
- 모든 키 중 사용 빈도가 가장 낮은 키(Least Frequently Used, LFU)를 제거.
- volatile-lfu
- TTL이 설정된 키 중 사용 빈도가 가장 낮은 키 제거.
로컬 캐시와 리모트 캐시
원래 로컬 캐시가 인메모리 캐신데 이걸 레디스에서 써버리면서 용어가 이상해져버림 그래서 그냥 로컬 캐시, 리모트 캐시 이렇게 나눠서 불르는게 명확함
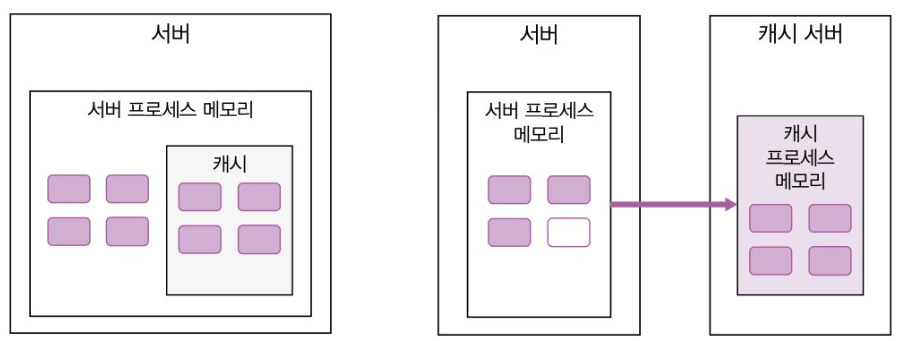
서버 프로세스 메모리에 캐시를 둘거냐, 아니면 네트워크를 타서 외부 서버의 캐시 메모리를 쓸거냐.
로컬 캐시의 특징:
- 당연히 메모리량에 물리적인 한계가 있고, 마이크로서비스에서 적합하지 않다.
- 서버를 재시작하면 메모리가 초기화된다.
리모트 캐시의 특징:
- 단점은 속도에 있다. 당연히 네트워크 통신을 해야하는데 속도가 느릴 수 밖에 없다.
- 별도의 서버와 프로세스가 필요해서 시스템 복잡성이 좀 올라가긴 한다.
- 근데 뭐 쩔수 있나, MSA 할려면 리모트캐시 써야지.
캐시 사전 적재
트래픽이 순간적으로 급증하거나, 새로 캐시 서버를 올린다? 그러면 사전 적재를 고려해야 한다. (Cache Warming) 이렇게 캐시를 사전 적재하면 큰 효과를 볼 수 있다.
예시:
- 앱 사용자 300만명
- 매달 정해진 날 사용자에게 요금 정보를 보여줌
- 해당 일자에 사용자들에게 푸시 알림 날라감
- 푸시 받은 사용자 중 일부가 조회를 함
만약 여기서 50%가 조회를 한다? 150만명이 한번에 조회를 한다는건데, 캐시에 아무것도 없으면 그냥 DB에 다른 데이터 150만개에 대한 조회가 때려지는거다. (서버가 안 죽는게 신기해진다)
이처럼, 히트율이 낮아지면 응답시간과 DB부하로 이어진다. 그래서 사전 적재를 통해 히트율을 높여주면 좋다
캐시 무효화
캐시 사용할 때 중요한건 유효하지 않은 데이터를 적절한 시점에 캐시에서 날려주는 것이다. (유효하지 않은 데이터란 오래된 데이터가 아니라 데이터의 원본 변경이 일어나 진짜로 유효하지 않은 데이터를 의미한다)
캐시에 보관한 원본이 바뀌면, 이에 맞춰 캐시에 보관된 데이터도 달라져야 한다. 이거 안하면 잘못된 정보가 사용자에게 보여진다는 거고 당연히 이건 큰 문제다.
그래서 데이터 특성에 따라 무효화 시점을 달리해서 설정해야한다. 민감한 데이터는 당연히 데이터가 변경되는 시점에 바로 변경해야 한다.
이때, 변경에 민감한 데이터는 리모트 캐시에 넣는거다. 로컬 캐시에 넣으면 자기꺼만 바꿔서 다른 서버꺼는 안 바뀐다. 만약 바꾸려면 복잡하게 짜야할거다.
변경에 민감하지 않다면 적절히 유효 시간을 설정을 해서 갱신해주면 된다. 최근 인기글 목록 이런건 솔직히 영향이 별로 없다. 그래서 그냥 주기적으로 갈아주는게 낫다.
가비지 컬렉터와 메모리 사용
많은 요즘 언어들이 가비지 컬렉터를 쓰고, JVM을 쓰는 자바는 더 중요하다.
힙 메모리에서 사용이 끝난 객체를 일정 주기나 힙 메모리가 일정 비율을 초과하면 GC가 돌면서 제거한다. 문제는 가비지 컬렉터가 실행되는 동안에는 애플리케이션이 중단되고, 이걸 Stop the World라고 한다.
당연히 메모리를 많이 사용하고, 생성된 객체가 많을수록 객체를 찾는 시간이 오래걸린다. 당연히 메모리를 줄인다? → GC 실행 주기나 실행 시간이 줄어든다.
그래서 힙 메모리 사이즈 조절도 중요하다. 줄이면 GC가 탐지하고 제거하는 시간이 줄어들겠지만, 그렇다고 막 줄이면 애플리케이션이 정상 작동하지 않거나 GC가 너무 자주 돌 수도 있다.
그래서 한번에 대량으로 객체를 생성하는 것도 주의해야한다. 객체를 한번에 대량으로 생성하면 그만큼 힙 메모리를 잡아먹게 되는데, 문제는 한방에 힙 사이즈보다 더 큰 용량을 생성하게 되면 당연히 맛탱이가 간다. GC가 돌아서 객체 제거를 해도 메모리 부족 상태가 다시 지속된다.
그래서 대량 객체가 생성되는 것을 막기 위해 조회 범위를 제한하거나 파일을 쪼개서 다운 받아야 한다.
- 10년치 조회 → 금지하고 3개월치 조회만 가능
- 4MB파일 다운 받기 → Stream으로 쪼개서 8KB씩 다운받기
응답 데이터 압축
응답 시간에는 데이터 전송 시간이 포함된다.
이 전송 시간은 2가지 요인에 영향을 받는다.
- 네트워크 속도
- 전송 데이터 크기
네트워크 속도가 너무 느려도 응답 시간이 길어진다. 응답 데이터가 너무 커도 당연히 시간이 길어진다.
그래서 정적 파일들을 압축해서 데이터 전송량과 전송 시간을 크게 줄일 수 있다.
ex) Html, CSS, JS, JSON, TXT
압축은 비용에도 영향을 준다. 클라우드에서는 트래픽 자체가 비용으로 직결되기 때문이다.
정적자원과 동적자원의 구분
동적자원
- 브라우저가 요청할 때마다 결과가 바뀌는 데이터
- 예: 제품목록 HTML, 제품상세 JSON 응답
정적자원
- 같은 URL에 대해 같은 데이터를 응답하는 콘텐츠
- 예: 이미지, JS, CSS 파일
- 전체 트래픽에서 상당한 비중 차지 (온라인 쇼핑몰의 경우 약 80%)
브라우저 캐시 활용
캐시의 필요성
- 동일한 정적자원을 매번 다운로드하면 불필요한 트래픽 발생
- 서버 비용 증가 및 브라우저 로딩 속도 저하
캐시 동작 방식
- HTTP의 Cache-Control, Expires 헤더 사용
- 예:
Cache-Control: max-age=60(60초간 로컬 캐시 사용) - 로컬 캐시에서 불러와 처리 속도 향상
브라우저 캐시의 한계
- 브라우저 단위로만 동작
- 동시 접속자 증가 시 여전히 네트워크 포화 문제 발생
CDN(Content Delivery Network) 활용
CDN의 구조와 장점
- 지역별 에지 서버 운영으로 지리적으로 가까운 서버에서 콘텐츠 제공
- 오리진 서버의 트래픽 감소
- 콘텐츠 전송 속도 향상
- 트래픽 비용 절감
CDN 동작 원리
- 사용자가 CDN URL로 콘텐츠 요청
- CDN에 콘텐츠가 없으면 오리진 서버에서 가져와 캐시에 보관
- 이후 동일 요청은 캐시된 데이터로 응답
정적파일 관리 시 주의사항
파일 크기 관리의 중요성
- 실수로 대용량 파일(예: 30MB 이미지) 업로드 시 비용 급증
- 트래픽 초과로 서비스 불능 상태 가능성
예방 방법
- 웹서버에 파일 크기 제한 설정
- 일정 크기 초과 시 에러코드 응답하도록 구성
대기행렬을 통한 트래픽 폭증 대응
트래픽 폭증 상황
- 콘서트 예매 등 순간적으로 사용자가 몰리는 경우
- 짧은 시간(1시간 이내) 동안만 트래픽 급증
기존 해결책의 문제점
- 서버 및 DB 증설의 높은 비용
- 전체 서비스 시간 중 1%도 안 되는 시간을 위한 고정비용 증가
- DB는 증설 후 축소가 어려워 지속적인 비용 부담
핵심 정리
- 성능 지표: 응답시간(TTFB, TTLB)과 처리량(TPS, RPS)이 핵심
- 병목 지점 파악: 모니터링을 통해 DB 연동과 외부 API 연동에서 주로 발생
- 커넥션 풀: DB 성능 개선의 핵심, 적절한 크기 설정과 유효성 검사 중요
- 캐시 활용: 로컬/리모트 캐시 구분, 적중률 향상과 무효화 전략 필요
- 정적 자원 최적화: 브라우저 캐시, CDN 활용으로 트래픽 비용 절감
실무 적용 포인트
- 모니터링 우선: 성능 개선 전 현재 상태 파악이 필수
- 점진적 개선: 급한 불은 수직 확장으로, 근본적 해결은 수평 확장으로
- 캐시 전략: 데이터 특성에 따른 캐시 무효화 정책 수립
- 비용 고려: CDN, 압축 등을 통한 트래픽 비용 최적화
다음 챕터 미리보기
다음 챕터에서는 데이터베이스 성능 최적화와 인덱스 전략에 대해 알아보겠습니다.
이 스터디는 매주 일요일 진행되며, 실무에서 바로 적용할 수 있는 백엔드 지식을 다룹니다.