JPA와 영속성 컨텍스트(Chapter 2)
JPA와 영속성 컨텍스트(Chapter 2)
이전 이야기…
Techeer Good Night Hackathon
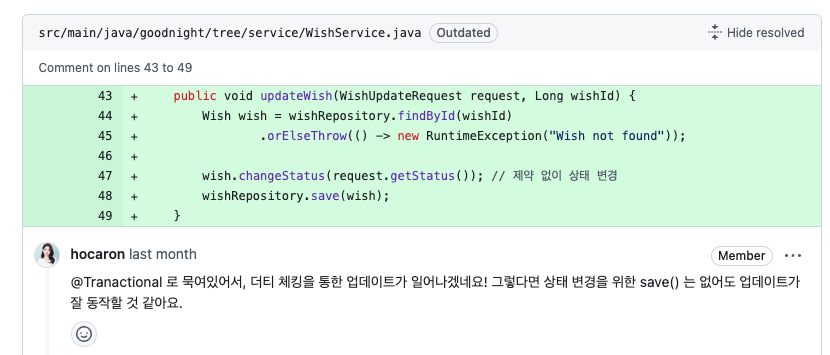
이전에 테커에서 Good Night Hackathon을 진행했다.(꽤 됐지만 블로그는 지금 작성…) 필요한 요구 조건에 맞춰 개발을 진행하고 현직자분께 코드 리뷰를 받을 수 있는 기회가 있어 참여하게 되었다.
Good Night 3rd Hackathon Backend
피드백을 통해 JPA에 대한 이해도가 떨어진다는 것을 알았고, 이를 해결하기 위해 JPA의 영속성 컨텍스트에 대해 개념적인 내용을 공부했다. 엔티티 매니저 팩토리와 엔티티 매니저, 트랜잭션, 영속성 컨텍스트의 기본 개념이 그 내용이다.
영속성 컨텍스트 왜 쓸까?
이전 Chapter를 통해, 간단하게나마 영속성 컨텍스트가 뭔지는 알게 되었다. 그렇다면 이 개념 왜 있는 걸까? 나는 운영체제 시간에 배우는 가상 메모리를 떠올리게 됐는데, 가상 메모리의 이점처럼 영속성 컨텍스트 즉 가상 데이터베이스를 활용하는 것은 큰 장점이 있다.(물론 가상 메모리와 같은 개념은 아니다 그냥 떠오른거다) 다음 5가지가 바로 그 장점들이다.
- 1차 캐시
- 동일성 보장
- (트랜잭션을 지원하는) 쓰기 지연
- 변경 감지
- 지연 로딩
그럼 하나하나 알아보자.
1차 캐시
영속성 컨텍스트 내부에는 캐시를 갖고 있는데 이것을 1차 캐시라고 한다. 영속 상태의 엔티티는 모두 이곳에 저장된다. 쉽게 얘기하면, 영속성 컨텍스트 내부에 Map이 하나 있는데 Key는 식별자(@Id), Value는 엔티티 인스턴스인 캐시다.
1
2
3
4
5
6
//엔티티 생성 및 값 부여(비영속)
Member member = new Member();
member.setId(100L);
member.setName("John");
// member 영속
em.persist(member);
이 코드를 실행하면 아래 그림처럼 회원 엔티티를 저장한다. 당연히 이전 Chapter에서 말한 것처럼 Member 엔티티는 아직 실제 데이터베이스에는 저장되지 않았다.
그럼 엔티티를 조회도 해보자
1
2
Member member2 = em.find(Member.class, 100L);
System.out.println(member2.getName());
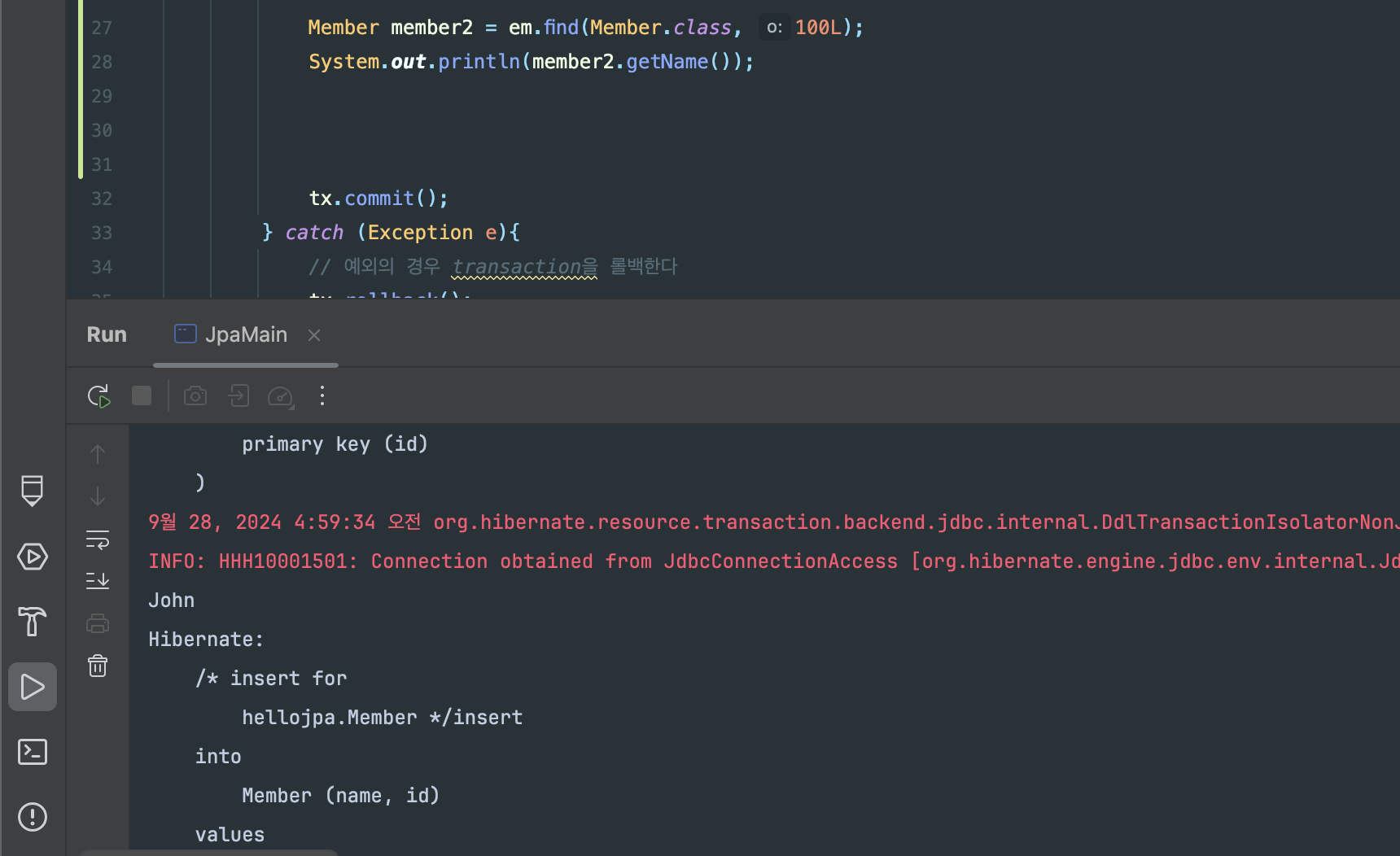
다음과 같이 엔티티를 찾아왔다. 이때 한 트랜잭션 안에서 Member를 영속하고 해당 Member를 Id를 통해 찾아왔기 때문에 쿼리 없이 1차 캐시에서 엔티티를 찾고 그 값을 가져왔다.
그럼, 엔티티가 1차 캐시에 없으면 어떻게 될까? h2 database에서 insert 쿼리문으로 100L, John을 넣고 em.find()로 해당 객체 조회를 사용했다.
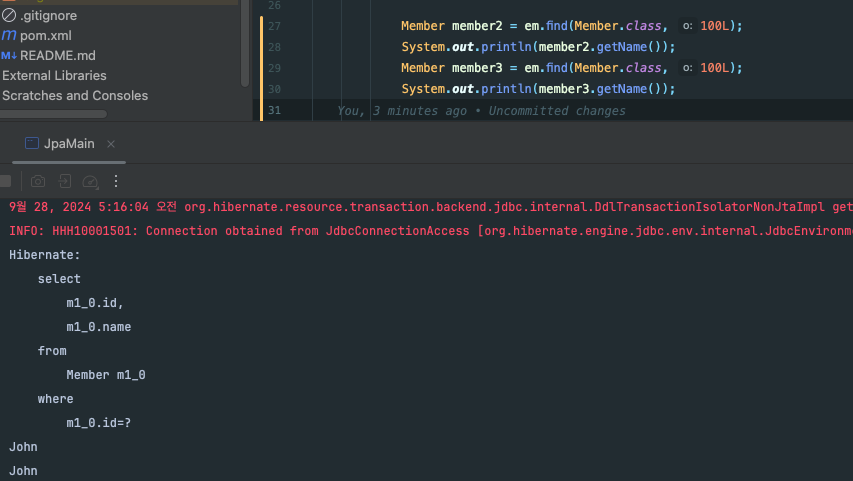
다음과 같이 1차 캐시에 해당 객체 정보가 없기 때문에, 직접 DB에 접근해서 값을 가져온다. 또 2번 조회를 했는데 1번만 쿼리가 날라간걸 볼 수 있는데, 이는 값을 조회해서 1차 캐시에 저장하고 해당 객체를 반환한 것이기 때문이다.
동일성 보장
- 동일성 비교 : 실제 인스턴스가 같다. ==을 사용해 비교한다.
- 동등성 비교 : 실제 인스턴스는 다를 수 있지만 인스턴스가 가지고 있는 값이 같다. equals()메소드를 구현해서 비교한다.
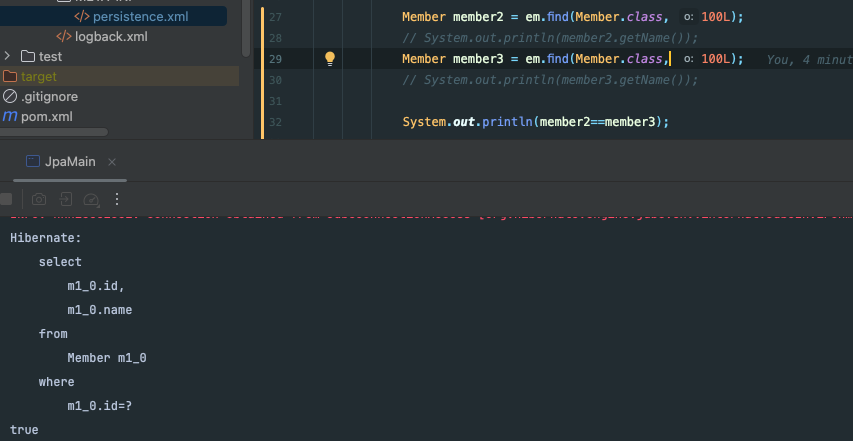
같은 Id를 조회한 member2와 member3를 ==으로 비교했을 때, true 값이 나온 것을 볼 수 있다. 즉, 인스턴스가 갖고 있는 값이 같다는 의미가 아니라 실제 인스턴스가 같다는 의미로 같은 엔티티 인스턴스를 반환(나는 C언어 포인터처럼 느껴졌다)했다는 것이다.
쓰기 지연
쓰기 지연은 em.persist(member)를 사용해 member를 저장해도 바로 INSERT 쿼리문이 날라가는 것이 아니라 트랜잭션을 커밋하기 직전까지 내부 쿼리 저장소에 INSERT SQL을 모아뒀다가 트랜잭션을 커밋할 때 모아둔 쿼리를 DB에 보내는 개념이다.
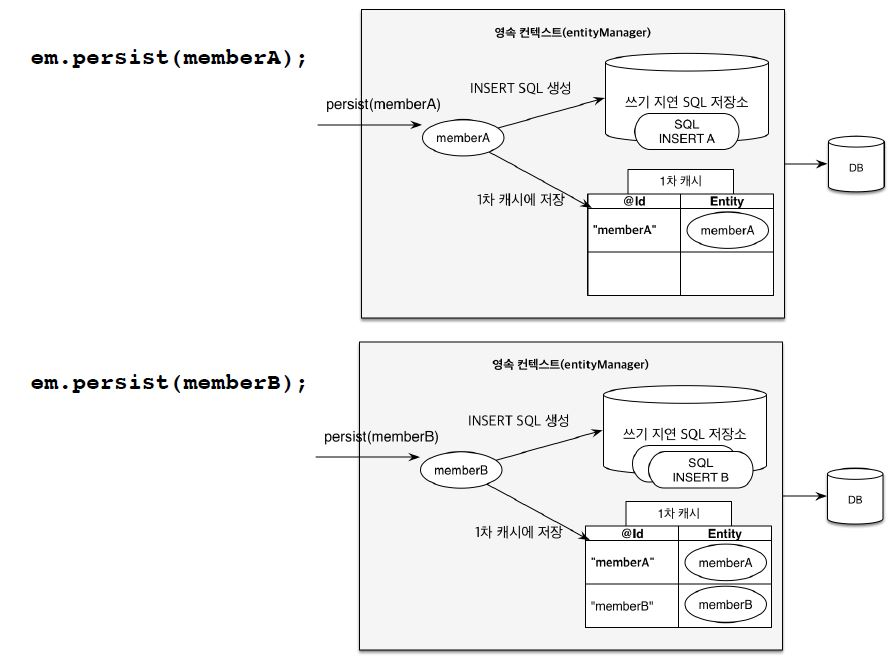
위 그림처럼 엔티티의 값은 1차 캐시에 저장하고, 관련 쿼리는 쓰기 지연 SQL 저장소에 저장하여 이후 트랜잭션을 커밋할 때 한번에 DB에 날리는 것이다.
+α(나만의 궁금증)
쓰기 지연을 통해 쿼리 문은 쓰기 지연 저장소에 엔티티는 1차 캐시에 저장한다고 했다. 그렇다면 SQL을 계속 저장했다가 커밋을 날릴 때, 여러 번 같은 인스턴스의 값을 변경한다면 SQL 쿼리도 여러번 날라갈까?
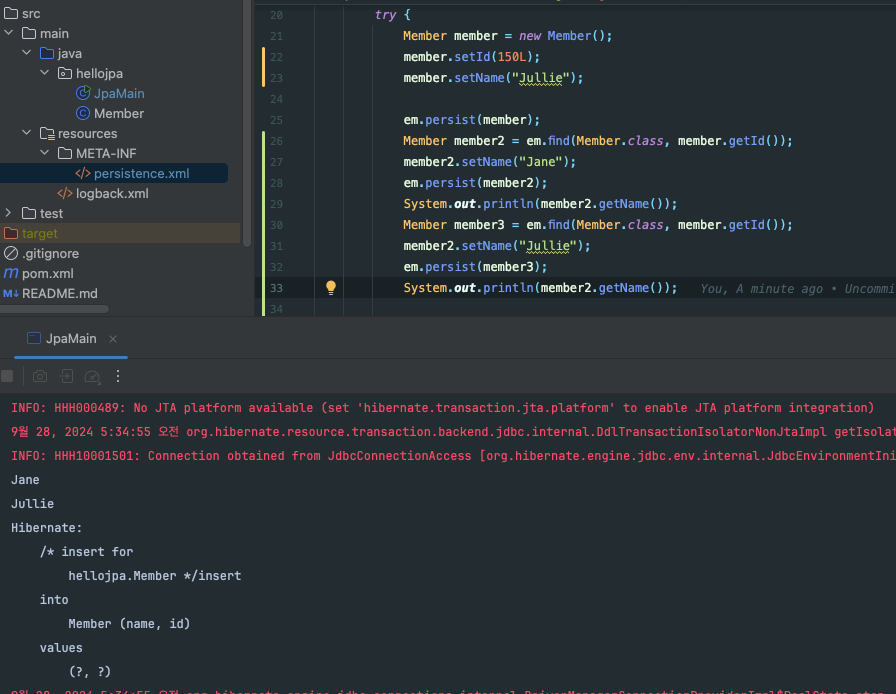
위 사진을 보면 알 수 있지만, 그런 일은 일어나지 않는다.
변경 감지
변경 감지 즉, 더티 체킹까지 와버렸다. 이전에 내가 받았던 코드리뷰에서 더티 체킹을 통한 업데이트가 일어나서 save()함수를 사용하지 않아도 된다고 했다. 이게 바로 그 내용이다. 영속성 컨텍스트는 엔티티의 변경사항을 자동으로 데이터베이스에 반영하는데, 바로 이걸 변경 감지라고 하는 것이다.
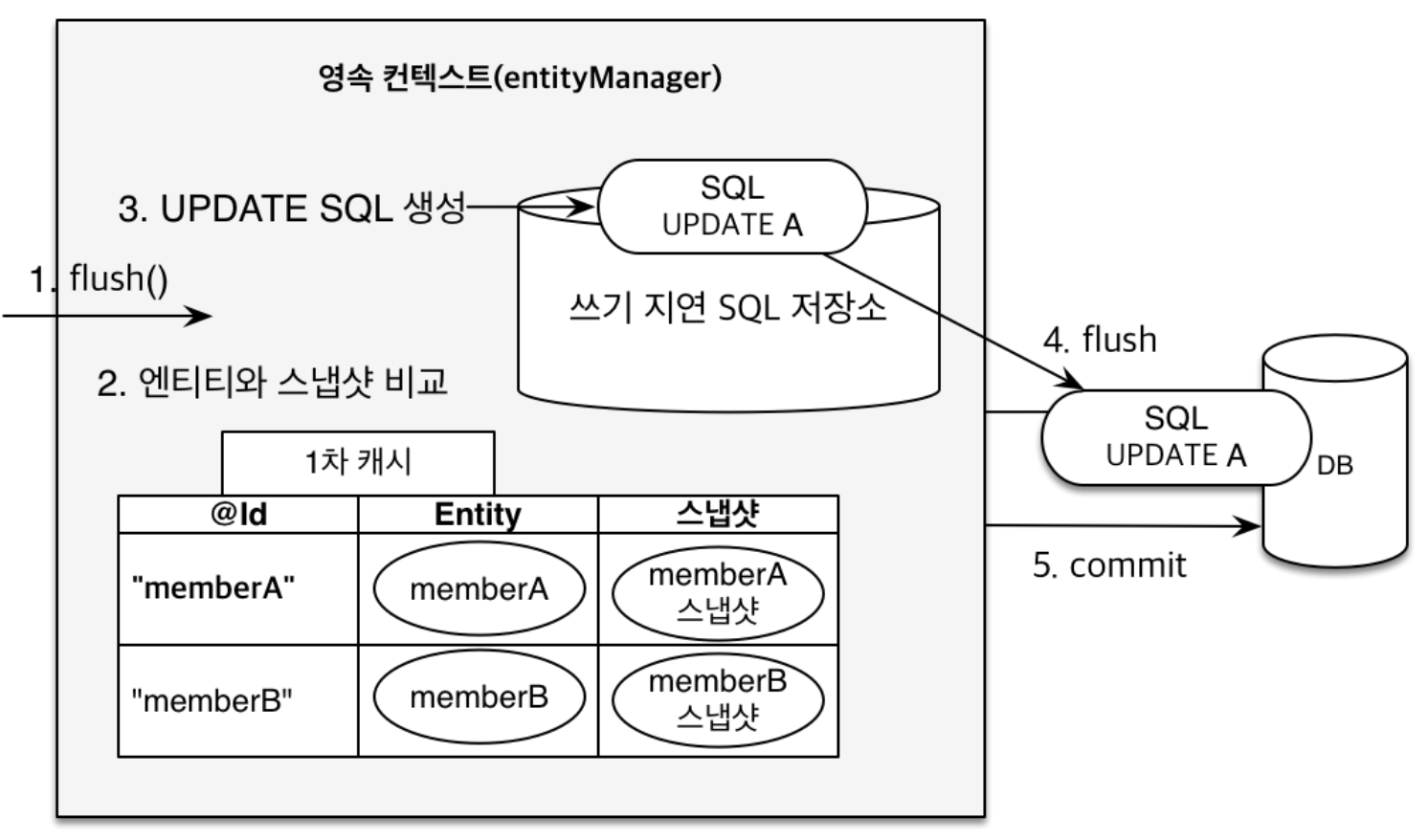
그림처럼 JPA는 엔티티를 영속성 컨텍스트에 보관할 때, 스냅샷(최초 상태를 복사해서 저장해둔 놈)을 남긴다. 그리고 Flush(실제 DB에 반영) 시점에 스냅샷과 엔티티를 비교해서 변경된 엔티티를 찾는다. 그리고 변경된 엔티티가 있다면 수정 쿼리를 생성해서 쓰기 지연 SQL 저장소에 보낸다. 그리고 실제 DB에 이 쿼리를 날리고, 트랜잭션을 커밋하는 것이다. 깃을 사용할 때도 develop 과의 변경 사항을 감지해서 자동으로 추적해는 것을 기억할 것이다. 그렇게 생각하면 이해하기 편하다.
지연 로딩
지연로딩은 이후 지연 로딩에 관한 피드백으로 다시 돌아오겠다.
결론은?
JPA는 Spring을 사용하는 많은 웹 개발자들이 필수적으로 사용하는 ORM이다. 나도 해커톤을 진행하면서 JPA를 사용했지만, 제대로 이해하지 않고 사용하다 보니 불필요한 코드가 들어갔다. 그래서 다들 JPA의 개념을 한번쯤은 공부하고 사용하는 게 좋을 것 같다.
추가적으로, 혼자서만 코드를 짜고 어떠한 피드백도 받지 못했다면, 아마 JPA에 대해 공부해야겠다는 생각을 못 했을 것 같다. 하지만 현업자분께 직접 코드 리뷰를 받고 나니, 단순히 코드가 개선되는 것뿐만 아니라 내가 앞으로 공부해야 할 부분과 현재 부족한 부분을 많이 알 수 있어서 좋았고, 개발에 흥미도 더 많이 느낄 수 있었다. 역시 개발은 혼자 하는 게 아니라 함께 하는 게 최고야! 그럼 이만~