Set in java (deepdive study)
Set
- 입력 순서를 유지 X, 데이터 중복 허용하지 않음
- 데이터에 null 입력 가능하나, 한 번만 저장하고 중복 저장을 허용하지 않음
- 인덱스가 따로 존재하지 않기 때문에 Iterator를 사용하여 조회
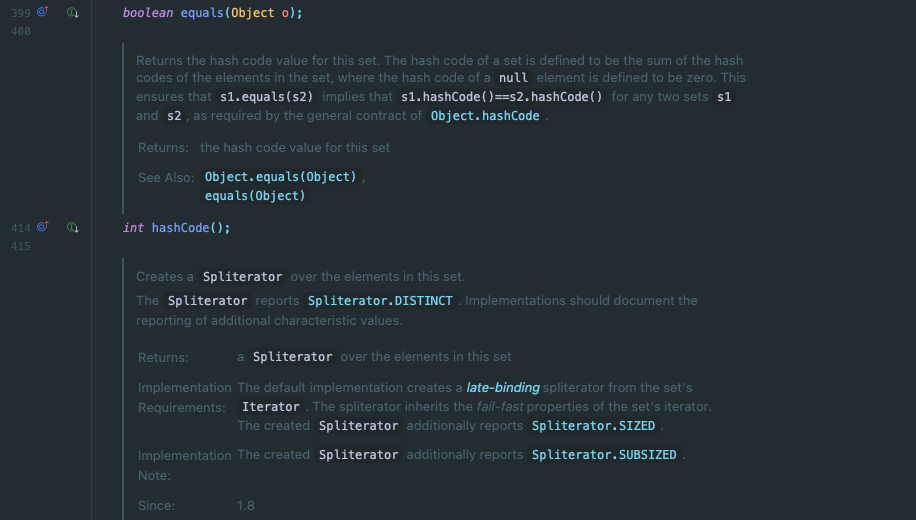
Set은 무엇보다도 데이터가 중복되는 것을 허용하지 않으므로, 데이터가 같은지를 확인하는 작업은 Set의 핵심 작업입니다. 따라서 equals()와 hashCode()메소드를 구현하는 부분은 Set에서 매우 중요합니다.
HashSet
1
Set<Integer> set = new HashSet<>();
1
2
3
4
java.lang.Object
- java.util.AbstractCollection<E>
- java.util.AbstractSet<E>
- java.util.HashSet<E>
AbstractCollection을 확장한 것은 ArrayList와 동일하지만 HashSet은 AbstractSet을 확장했습니다.
내부적으로 HashMap을 사용
HashMap이란?
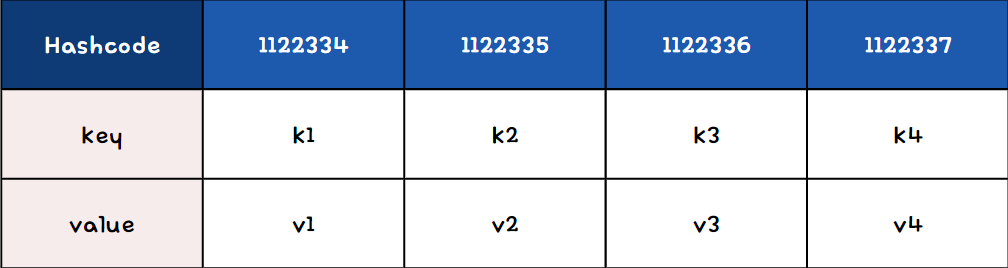
간단하게 key, value로 이루어지며
해시함수(key) →
return 해시코드 = 버킷의 인덱스
예시
해시 테이블 구현 코드 (클릭하여 펼치기)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
// 기본적인 해시 테이블 구현
public class Hash {
// Hash table
public Slot[] hashTable; // 배열 형태로 선언
// Hash 객체를 생성할 때 table 사이즈 지정
public Hash(Integer size) {
this.hashTable = new Slot[size];
}
// Slot에는 value를 가짐
public class Slot {
String value;
Slot(String value) {
this.value = value;
}
}
//Hash function
public int hashFunction(String key) {
return (int)(key.charAt(0)) % this.hashTable.length; // 나머지
}
// 입력 받은 key를 해시 함수로 인덱스화 하고, 해당 인덱스에 value 저장
public boolean saveData(String key, String value) {
// key는 해시 함수를 거쳐서 해시 값(해시, 해시 주소)을 반환 -> 여기선 배열의 index와 동일
Integer address = this.hashFunction(key);
if(this.hashTable[address] != null) { // 해당 주소에 이미 데이터가 있을 경우
this.hashTable[address].value = value;
} else {
this.hashTable[address] = new Slot(value);
}
return true;
}
// key에 해당하는 값을 반환
public String getData(String key) {
// key는 해시 함수를 거쳐서 해시 값(해시, 해시 주소)을 반환
Integer address = this.hashFunction(key);
if(this.hashTable[address] != null) {
return this.hashTable[address].value;
} else {
return null;
}
}
}
그럼 Hash table을 만들 때 Slot[] 형태로 선언하고 객체 생성 시 사이즈를 지정한다?
→ Static Allocation 형태다!
1
2
3
4
5
6
7
// Hash table
public Slot[] hashTable; // 배열 형태로 선언
// Hash 객체를 생성할 때 table 사이즈 지정
public Hash(Integer size) {
this.hashTable = new Slot[size];
}
근데 왜 크기 생각을 안하고 HashSet을 쓰지? → ArrayList 같은거
기본 용량이 있고 필요하면 사이즈를 늘리는 방식
HashSet(int initialCapacity)
- capacity를 변경할 수 있으며, load factor(0.75) 이다.
HashSet(int initialCapacity, float loadFactor)
- capacity와 load factor를 변경할 수 있다.
작동방식 capacity x load factor 만큼 용량이 차면 → 2배 사이즈 업
ex ) 16 x 0.75 = 12 , 용량 12 도달 시 32로 사이즈 업 이후 hash 함수를 거쳐 재배치
즉, resizing and rehashing 과정을 거침 (사이즈가 업 되는게 ArrayList에 비해 효율적인건 아님)
Capcity와 Load factor가 무엇일까 ?
HashSet의 내부는 HashMap으로 구현되어 있다. 데이터를 저장할 때 버킷이라는 배열에 저장한다. 처음부터 배열의 크기를 무한정 늘려 놓을 수가 없다. 만약 데이터를 조금만 저장한다면 남은 공간은 모두 낭비가 되기 때문이다. 그래서 Set은 처음의 배열의 크기 즉 데이터를 저장할 수 있는 공간인 capcity를 default로 16으로 설정해 둔다.
그렇다면 capacity를 넘어서 데이터를 저장하려고 하면 어떤일이 일어날까? 16개를 다 채운다음에 배열의 크기를 늘리는 것일까? 여기서 작용하는게 바로 load factor이다. load factor가 0.75이고 capacity가 16이라면, 16 * 0.75인 12의 공간에 데이터가 저장되면 capcity를 2배 늘려준다. 즉, 16의 공간이 다 쓰이기 전에 미리 저장 공간을 늘려 놓는다는 소리이다.
load factor가 너무 작으면, 아직 많이 쓰지도 않았는데 저장 공간을 키워 빈 공간이 많이 남아 비효율적일 위험이 크다.
출처 : 해시(HASH) 알아보기
TreeSet
- 객체를 중복해서 저장할 수 없다
- 저장 순서가 유지되지 않는다
- 대신 정렬은 되어있다
- HashSet보다 데이터의 추가와 삭제는 시간이 더 걸리지만 검색과 정렬에는 유리
TreeSet은 내부적으로 Red-Black Tree(레드-블랙 트리)를 기반으로 동작하는 이진 검색 트리(BST) 구조를 가진다. 즉, 데이터를 삽입하면 자동 정렬되며, 정렬된 상태를 유지하면서 데이터를 저장한다.
1. Red-Black Tree 개요
- 자기 균형(Binary Self-Balancing) 이진 검색 트리의 일종.
- 각 노드에 Red(빨강) 또는 Black(검정) 색깔 속성을 부여하여 트리의 균형을 유지.
- 트리가 한쪽으로 치우쳐지는 문제(편향 트리 Skewed Tree)를 방지하며, 최악의 경우에도 O(log N) 시간 복잡도를 보장.
- HashSet과 다르게
TreeSet은 정렬된 상태를 유지하므로 순서 기반 연산(subSet, headSet, tailSet 등)이 가능.

이진트리(Binary Tree)란?
이진트리(Binary Tree)는 트리 중에서도 각 노드가 최대 2개의 자식노드를 가질 때 이진트리(Binary Tree)라고 합니다.
최대 2개이기 때문에 자식이 없을 수도 있고, 한개만 있을 수도 있습니다.
이때 자식노드는 각각 왼쪽 자식노드와 오른쪽 자식노드로 표현을 합니다.
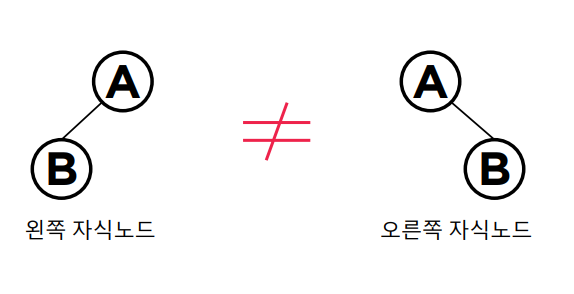
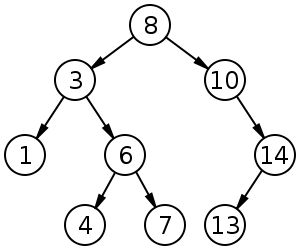
노드의 왼쪽 가지에는 노드의 값보다 작은 값들만 있고, 오른쪽 가지에는 큰 값들만 있도록 구성
n값에 대한 탐색이 이루어질 때, 루트 노드와 비교해서 n이 더 작다면 루트 노드보다 큰 값들만 모여 있는 오른쪽 가지는 전혀 탐색할 필요가 없다. 마찬가지로 루트 노드의 왼쪽 자식보다 n 이 크다면 왼쪽 자식의 왼쪽 가지는 탐색할 필요가 없고, 다시 말해 트리 자체가 이진 탐색을 하기에 적합한 구조가 되는 것
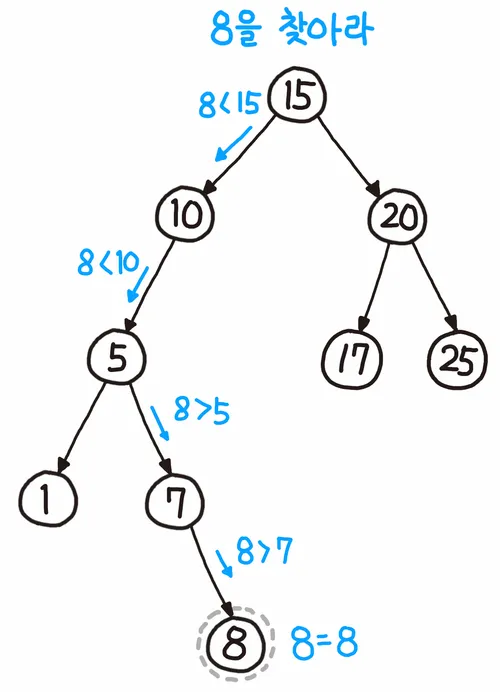
근데 다음과 같이 구성되어 있다면 효율성이 최악의 경우 O(N)이 됨(위와 같은 그림을 편향되었다고 함) → 즉 트리가 균등하게 분배되어 있어야 효율성이 좋아짐
그렇다면 Red-Black Tree는?
C++의 set, map뿐만 아니라 Java의 TreeMap, TreeSet 등도 레드-블랙 트리를 기반
대신 레드 블랙 개념을 도입해 Self Balance를 이루게 함
→ 즉 스스로 Tree를 균등하게 만들어 탐색 시 효율성이 최악이 나오는 경우를 제한함
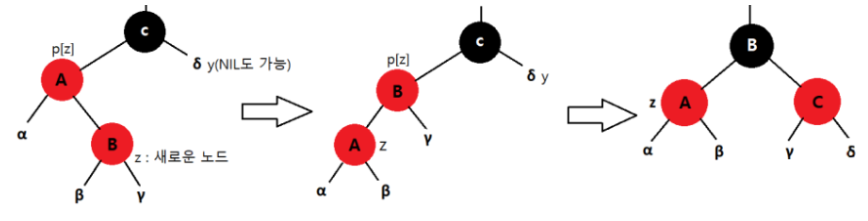
+ ɑ
Set의 다양한 구현체들을 살펴보면서 알게된 점들을 정리해보자면:
HashSet vs TreeSet 성능 비교
| 연산 | HashSet | TreeSet |
|---|---|---|
| 추가/삭제 | O(1) 평균 | O(log N) |
| 검색 | O(1) 평균 | O(log N) |
| 정렬 | 없음 | 자동 정렬 |
| 메모리 사용량 | 적음 | 많음 |
언제 어떤 Set을 사용할까?
HashSet 사용 시기:
- 빠른 검색이 필요한 경우
- 정렬이 필요하지 않은 경우
- 메모리 사용량을 최소화하고 싶은 경우
TreeSet 사용 시기:
- 정렬된 데이터가 필요한 경우
- 범위 검색이 필요한 경우 (subSet, headSet, tailSet)
- 데이터를 순서대로 처리해야 하는 경우
결론
Set을 공부하면서 알게된 것들을 정리해보자면:
- HashSet은 HashMap을 내부적으로 사용하여 O(1) 평균 성능을 제공한다
- TreeSet은 Red-Black Tree를 사용하여 자동 정렬과 O(log N) 성능을 보장한다
- Set은 중복을 허용하지 않으므로 equals()와 hashCode() 구현이 중요하다
- 용도에 따라 적절한 Set 구현체를 선택해야 한다
다음과 같은 Set의 특징을 알고 사용한다면, 이후에 관련한 이슈가 생기거나 성능에 대해 고민할 때 도움이 될 것이라고 생각한다.