List in java (deepdive study)
List in java (deepdive study)
서론
Spring을 사용하는 많은 사람들이 List 사용에 익숙할 것입니다.
하지만 List에 대해 깊게 신경쓰고 사용하기 보다는 대부분 습관적으로 사용하는 경우가 많다(제가 딱 그랬습니다).

특히 위와 같이 특정 Entity간의 N:1 매핑관계를 설정하는 경우가 많은데(N:M도 N:1, 1:M으로 사용), List에 대한 기본적인 자료구조를 알고 있기 때문에 더욱 신경쓰지 않고 사용할 것이라고 생각한다.
그래서 ArrayList, LinkedList, Vector와 같은 다양한 구현체가 있음에도 습관적으로 ArrayList를 사용할 뿐 다른 구현체는 신경쓰지 않는 경우가 대다수 일 것 같다(나도 그랬다). 그래서 이번에는 제대로 알아보고자 한다.
본론
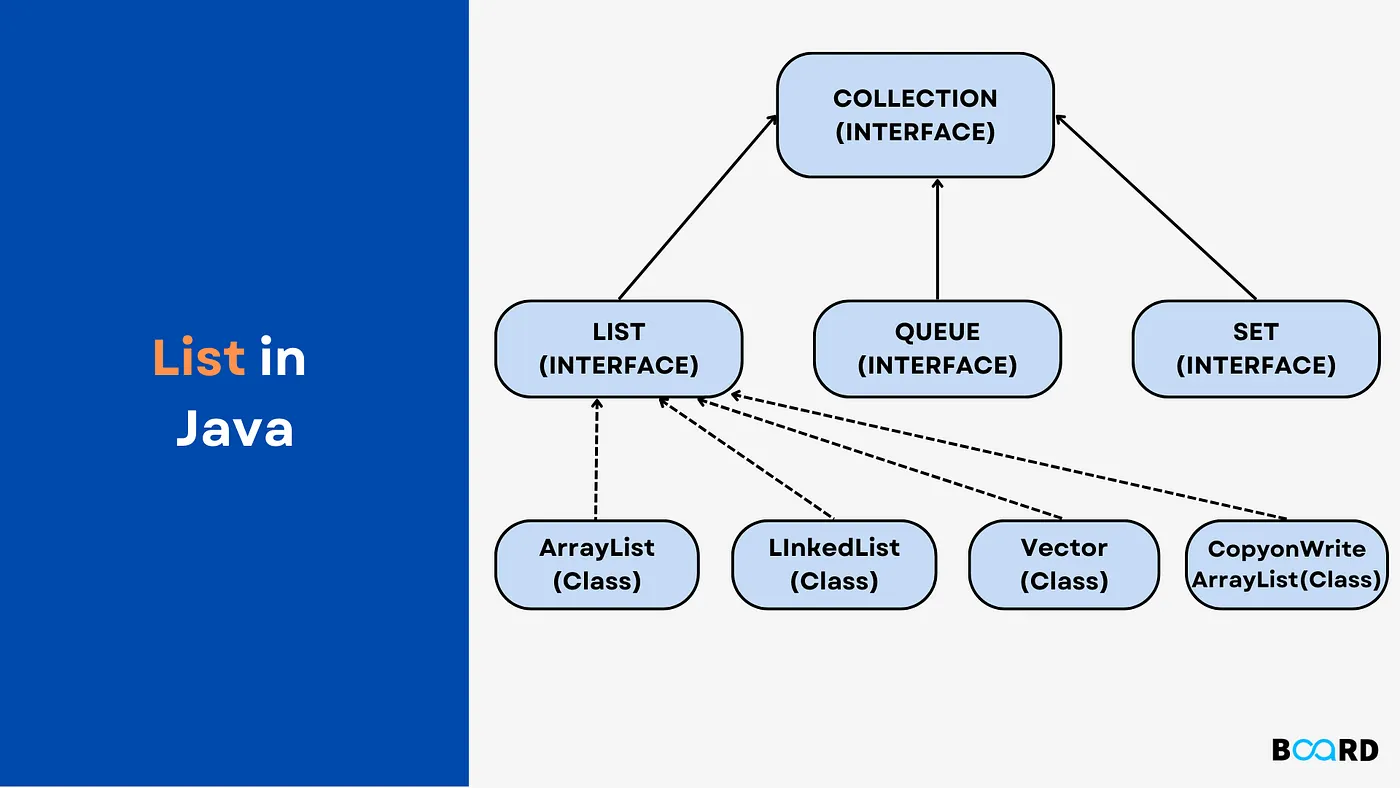
List (인터페이스)
- 입력 순서를 유지하며, 데이터의 중복을 허용
- 인덱스를 통해 저장 데이터에 접근이 가능
- 크기가 가변적이다.
주요 구현체
- ArrayList, LinkedList
- Vector 업그레이드 버전 → ArrayList
1. ArrayList
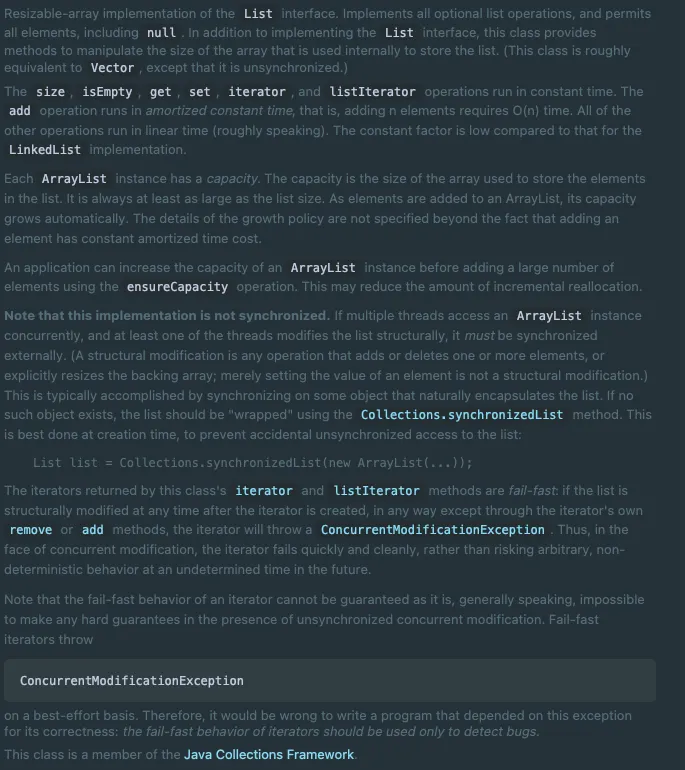
ArrayList는 동적 배열 기반의 List 구현체. 내부적으로 배열을 사용하며, 초기 용량(capacity)은 10, 추가 시 1.5배씩 증가.
CRUD 연산의 시간 복잡도
- get/set: O(1)
- add(element): O(1) (평균적으로)
- add(index, element) / remove(index): O(n)
Vector와 비슷하지만, 동기화되지 않음(unsynchronized). 멀티스레드 환경에서는 Collections.synchronizedList()를 사용해야 안전. Fail-Fast Iterator: 리스트가 구조적으로 변경되면 ConcurrentModificationException 발생. Fail-Fast는 100% 보장되지 않으며, 버그 감지 용도로만 사용해야 함.
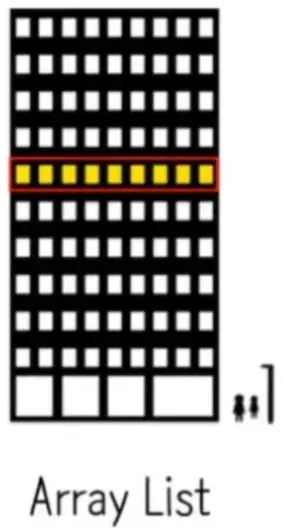
ArrayList는 기본 구성 방식이 배열이다.
그럼 간단하게 배열의 특징을 알아보자.
- 인덱스를 통한 O(1) 접근
- 고정된 크기
- 연속된 메모리 할당 (Cache Friendly) → 배열의 요소들은 메모리에서 연속적으로 저장되므로, 캐시 히트율(Cache Hit Rate)이 높아 성능이 향상됨.
궁금증
그렇다면, ArrayList는 기본 구성이 배열인데 어떻게 고정된 크기 (Static Allocation)가 아니라 동적 확장이 가능한걸까?
원소를 추가할 때 배열 크기가 부족해지면 새로운 배열을 생성한 뒤 기존의 원소들을 복사해 동적 확장
배열 용량 확인
원소가 추가될 때, 내부 배열(기본값 10)의 현재 크기가 부족한지 검사합니다.
새 배열 생성 및 복사
용량이 부족하면 새 크기(기존 배열 크기의 약 1.5배 정도)로 배열을 생성하고, System.arraycopy(…)를 통해 기존 배열의 요소들을 새 배열에 복사합니다.
참조 변경
내부에서 관리하는 배열 참조를 새 배열로 변경하여 동적으로 크기를 확장합니다.
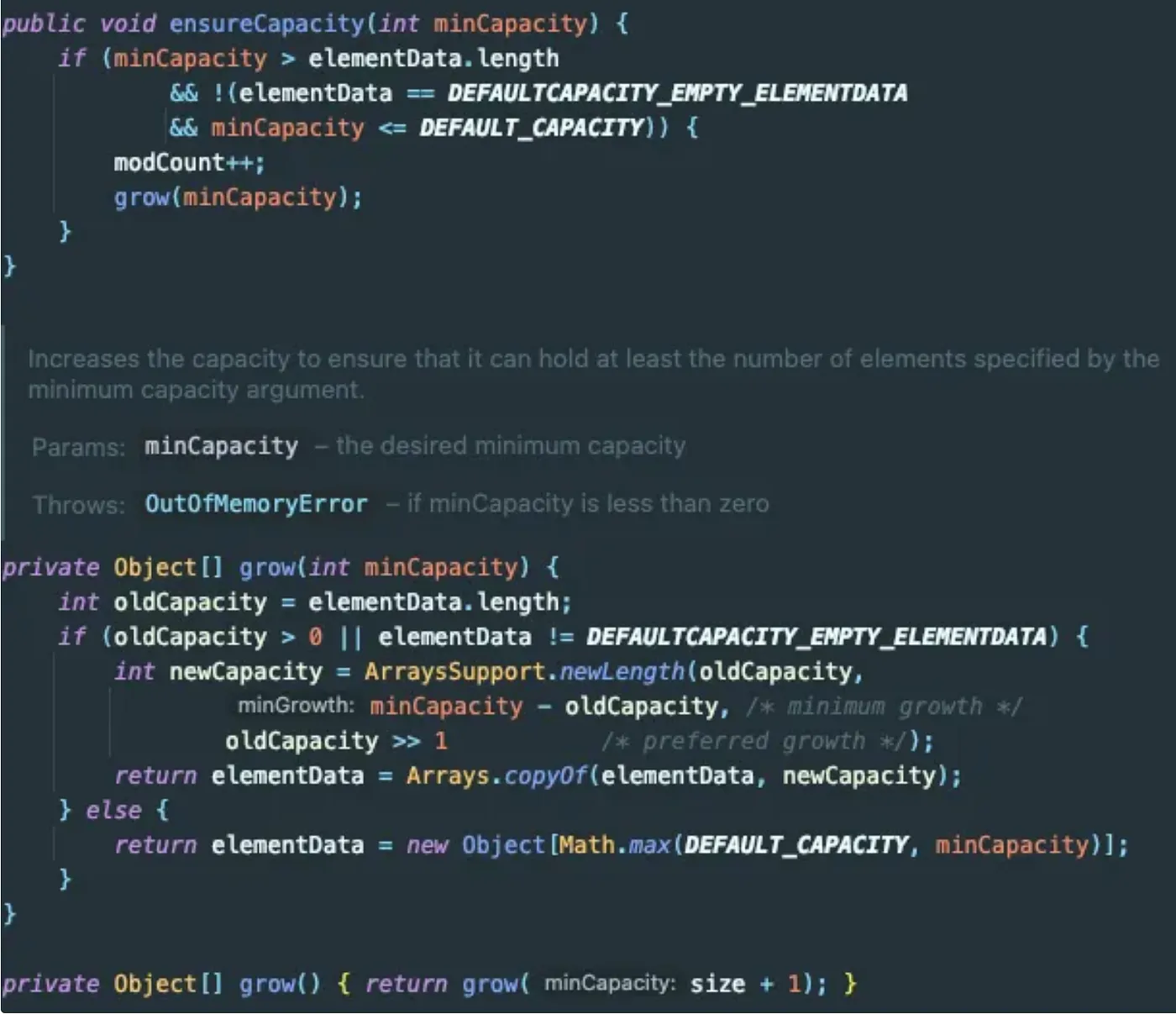
내부적으로 ArraysSupport.newLength(…) 메서드를 통해 새로운 배열 크기를 계산한 뒤, Arrays.copyOf(…)를 활용하여 기존 배열을 복사하고 참조를 업데이트합니다. 간단히 동작 과정을 정리하면 다음과 같습니다:
함수 동작 정리
1. ensureCapacity(int minCapacity) : 용량 확인
- elementData.length(현재 배열의 길이)보다 minCapacity(필요 최소 용량)가 큰 경우 실행
2. grow(int minCapacity) : 용량 늘리기
- prefGrowth = oldCapacity » 1현재 배열 용량의 절반(= 1/2)을 선호하는 증가량
- ArraysSupport.newLength(…) 내부에서 Math.max(oldLength + prefGrowth, oldLength + minGrowth) 형태의 계산을 통해 필요한 최소 공간과 선호하는 증가량 중 큰 값을 택하고, 오버플로 등을 검사하여 최종 크기를 결정합니다.
- 최종 계산된 newCapacity만큼 배열을 재할당(Arrays.copyOf(elementData, newCapacity))하여 용량을 늘립니다.
- 만약 oldCapacity가 0이거나 elementData가 DEFAULTCAPACITY_EMPTY_ELEMENTDATA(빈 배열)일 경우, DEFAULT_CAPACITY(기본값 10) 또는 minCapacity 중 큰 값으로 새 배열을 생성합니다.
정리하면, 기본 크기가 10인 배열에서 시작해 동적으로 크기가 부족해질 때마다 기존 배열의 약 1.5배 수준으로 확장됩니다. 이 동작 덕분에 개발자는 ArrayList 용량을 미리 지정하지 않아도 자동으로 확장되며, 필요에 따라 ensureCapacity(int minCapacity)를 통해 미리 용량을 늘려 성능을 최적화할 수 있습니다.
2. LinkedList
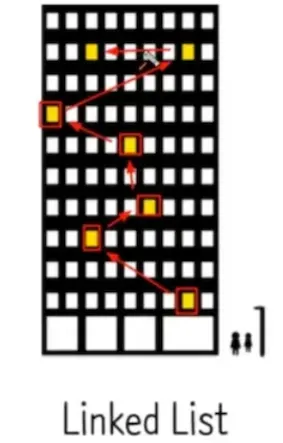
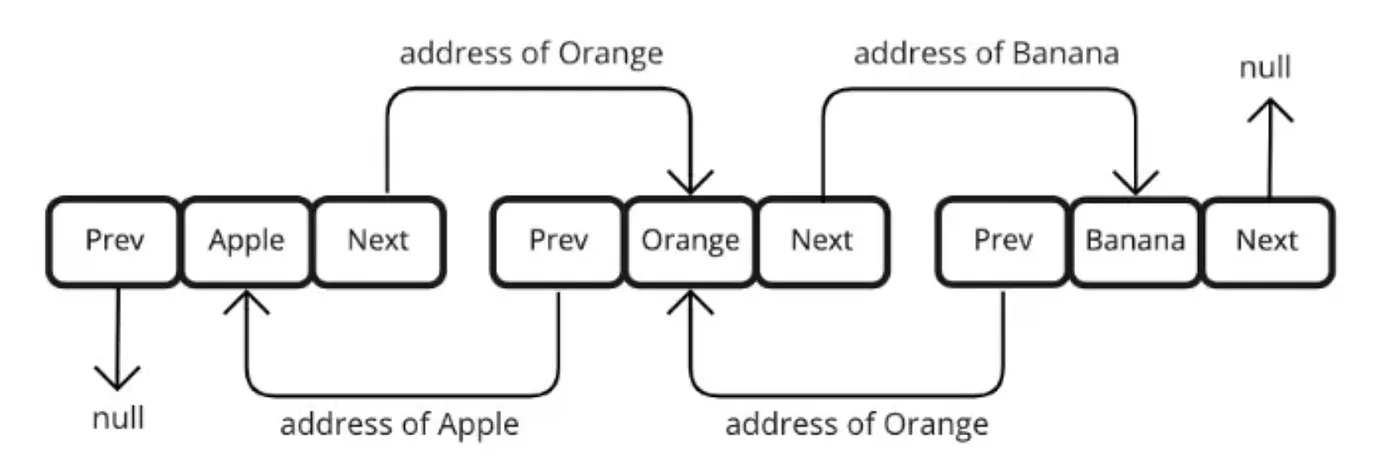 우리가 아는 이중 연결 리스트(doubly linked list) 구조
우리가 아는 이중 연결 리스트(doubly linked list) 구조
노드로 구성: 이전, 이후 노드의 주소값, 데이터 값
LinkedList에서 사용하고 있는 실제 Node 객체
1
2
3
4
5
6
7
8
9
10
11
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
3. ArrayList vs LinkedList
보통 ArrayList 와 LinkedList 중에 어느걸 사용하면 되냐고 묻는다면, 삽입 / 삭제가 빈번하면 LinkedList를, 요소 가져오기가 빈번하면 ArrayList를 사용하면 된다 라고들 가르쳐 주지만, 사실 성능면에서 둘은 큰 차이가 없다.
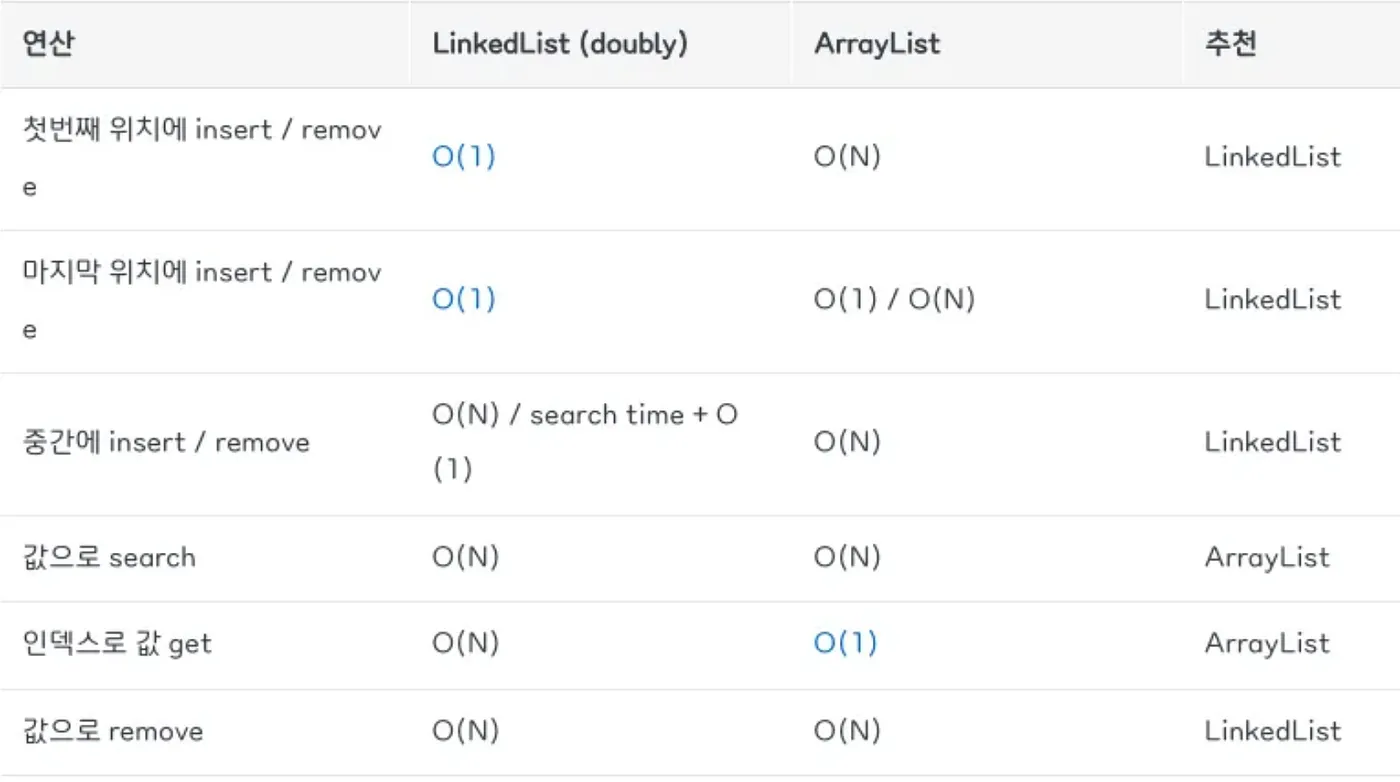
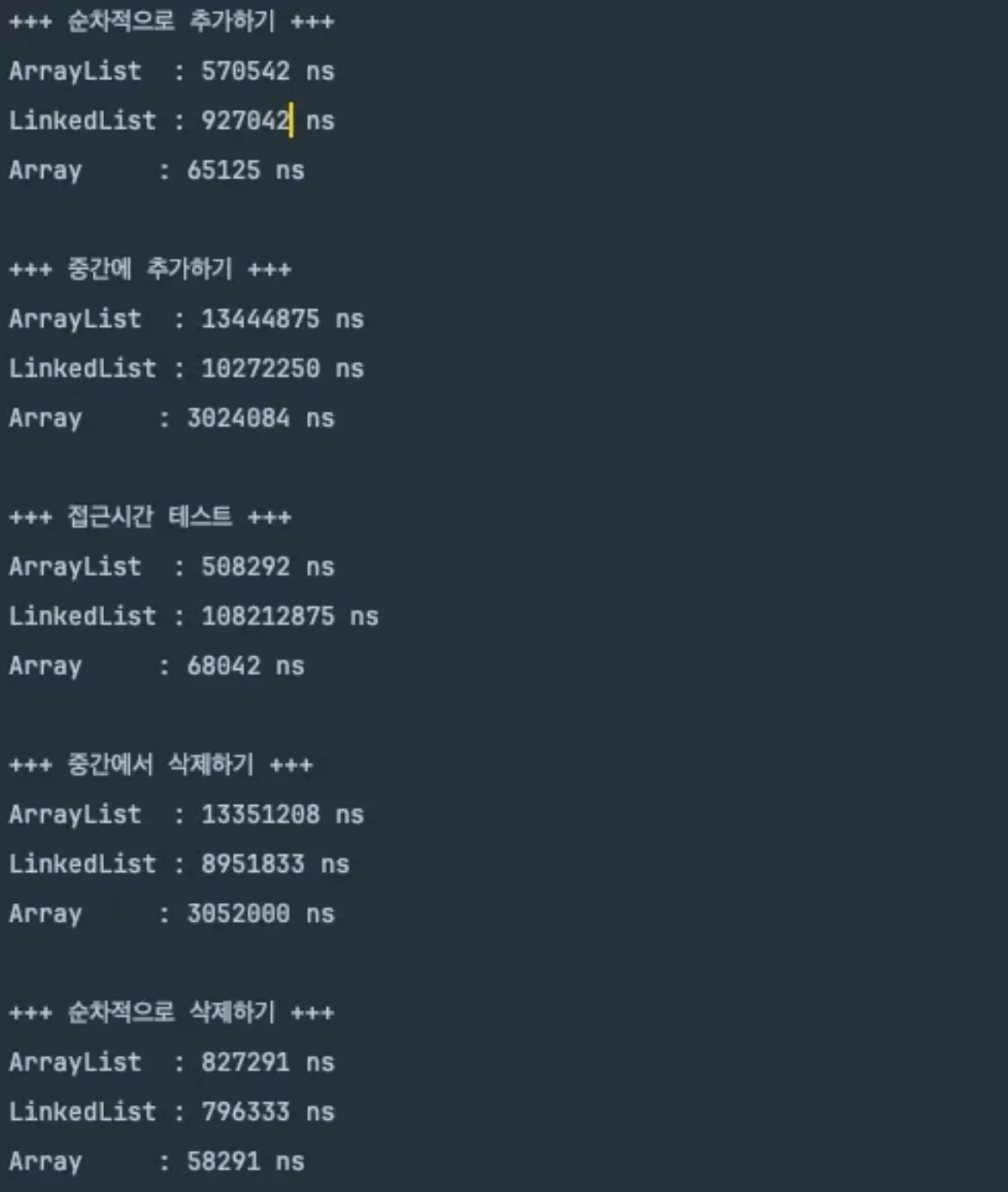
예를들어 ArrayList는 리사이징 과정에서 배열 복사하는 추가 시간이 들지만, 배열을 새로 만들고 for문을 돌려 기존 요소를 일일히 대입하는 그러한 처리가 아니라, 내부적으로 잘 튜닝이 되고 최적화 되어있어 우리가 생각하는 것처럼 전혀 느리지않다.
위의 성능 코드 예시 역시 두각을 나타내기 위해 극단적으로 나노초로 비교해서 차이가 확연히 보여서 그렇지 체감상 차이가 그리 큰 편도 아니다.
또한 외국 사례를 검색하여 살펴보면 LinkedList를 사용하는 사례보다 그냥 ArrayList를 사용하는 사례가 많은데, 자바의 컬렉션 프레임워크 등 자바 플랫폼의 설계와 구현을 주도한 조슈아 블로치(Joshua Bloch) 본인도 자신이 설계했지만 사용하지 않는다고 말할 정도이다
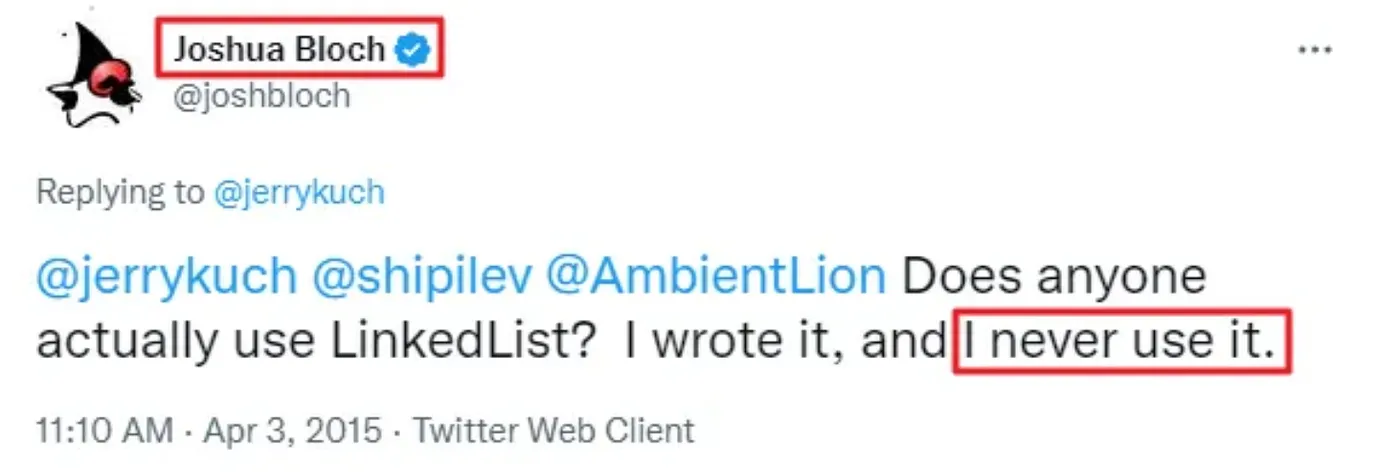
몇몇 분들은 FIFO(선입선출)이 빈번할 경우, ArrayList 경우 첫번째에 요소를 추가할 때마다 자주 데이터 이동(shift)가 일어나기 때문에 큐(queue)를 사용해야 할때 LinkedList를 사용한다 라고 말하지만, 차라리 그런경우엔 따로 ArrayDeQue라는 더욱 최적화된 컬렉션을 쓰는 것이 훨씬 좋다.
출처 : 🧱 ArrayList vs LinkedList 특징 & 성능 비교
+α (나만의 궁금증)
분명히 ArrayList의 특징에서 비동기적 특징을 보았다.
Vector와 비슷하지만, 동기화되지 않음(unsynchronized). 멀티스레드 환경에서는 Collections.synchronizedList()를 사용해야 안전.
그러면 우리가 Spring에서 ArrayList를 사용할 때 동시성 문제를 고려해야 하지 않을까?
맞다. 동시성 이슈를 고려해야 한다.
Spring은 멀티스레드 환경에서 동작하므로, ArrayList를 공유 자원으로 사용할 때는 반드시 동시성 문제를 고려해야 한다.
Spring에서의 동시성 문제
Spring에서 ArrayList를 사용할 때 발생할 수 있는 동시성 문제들:
- 동시 수정 문제: 여러 스레드가 동시에 ArrayList를 수정할 때 데이터 불일치 발생
- Fail-Fast Iterator: 구조적 변경 시 ConcurrentModificationException 발생
- 메모리 가시성 문제: 한 스레드에서 수정한 내용이 다른 스레드에서 보이지 않을 수 있음
해결 방법들
1. ThreadLocal 사용
ThreadLocal이란 Java에서 지원하는 Thread safe한 기술로 멀티 스레드 환경에서 각각의 스레드에게 별도의 저장공간을 할당하여 별도의 상태를 갖을 수 있게끔 도와준다.
ThreadLocal 코드 예시 (클릭하여 펼치기)
1
2
3
4
5
6
7
8
private static final ThreadLocal<List<String>> threadLocalList =
ThreadLocal.withInitial(ArrayList::new);
// 각 스레드마다 별도의 ArrayList 인스턴스를 가짐
List<String> list = threadLocalList.get();
// 사용 후 반드시 정리해야 함
threadLocalList.remove();
장점: 각 스레드가 독립적인 ArrayList를 가지므로 동시성 문제 없음 단점: 메모리 사용량 증가, ThreadLocal 정리 필요
참고 자료: Thread Local이란 무엇일까
2. 동기화된 Collection 사용
동기화된 Collection 코드 예시 (클릭하여 펼치기)
1
2
3
4
5
6
7
8
// Collections.synchronizedList() 사용
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<>());
// 사용 시 반드시 synchronized 블록으로 감싸기
synchronized(synchronizedList) {
synchronizedList.add("item");
// 다른 작업들...
}
3. Concurrent Collection 사용
Concurrent Collection 코드 예시 (클릭하여 펼치기)
1
2
3
4
5
6
7
8
9
10
11
12
// CopyOnWriteArrayList 사용 (읽기 성능 우선)
List<String> copyOnWriteList = new CopyOnWriteArrayList<>();
// ConcurrentLinkedQueue 사용 (큐 형태)
Queue<String> concurrentQueue = new ConcurrentLinkedQueue<>();
// 사용 예시
copyOnWriteList.add("item1");
copyOnWriteList.add("item2");
concurrentQueue.offer("queueItem1");
concurrentQueue.offer("queueItem2");
참고 자료: Is there a concurrent list in Java’s JDK?
Spring에서의 실제 사용 패턴
Spring에서는 보통 다음과 같은 패턴으로 동시성 문제를 해결한다:
- Request Scope: 각 HTTP 요청마다 별도의 인스턴스 생성
- ThreadLocal: 스레드별 독립적인 데이터 관리
- 불변 객체: 한 번 생성 후 수정하지 않는 방식
- 동기화된 Collection: 필요시에만 사용
결론
ArrayList를 공부하면서 알게된 것 크게 4가지를 정리해보자면
- ArrayList는 기본 구성이 배열이다
- 그래서 메모리 구조가 연속적이다
- 동적 할당은 Capacity가 가득차면 1.5배를 늘리는(grow) 방식으로 진행된다
- 인덱스를 통해 접근 가능하다
다음과 같은 List의 특징을 알고 사용한다면, 이후에 관련한 이슈가 생기거나 성능에 대해 고민할 때 도움이 될 것이라고 생각한다.