Database Join
조인(Join)이란?
관계형 데이터베이스에서는 데이터가 테이블로 쪼개져 있다.
조인이란 이 관계형 데이터베이스에서 복수의 테이블을 결합하는 것으로, 데이터 조회 시 다른 테이블의 데이터를 함께 조회해야할 때 이용한다. 관계형 데이터베이스는 수학 집합론의 관계형 이론에서 유래하여 데이터를 집합으로 간주해 다루기 때문에 조인에 대해 이해할 때 수학 집합을 떠올리면 좀 더 이해하기 쉬울 것이다.
Inner Join
먼저 Inner Join에 대해 알아보자.
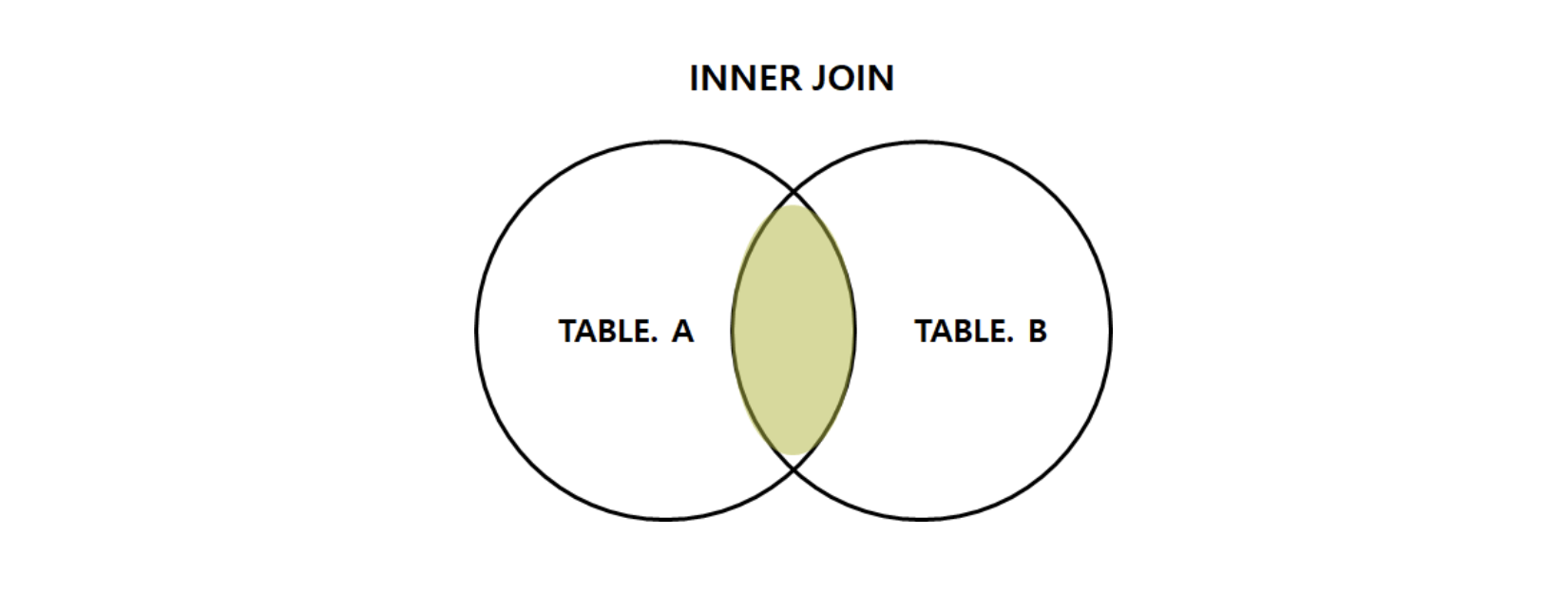
Join은 수학 집합을 떠올리라고 했는데, Inner 조인은 A와 B의 교집합이라고 보면 된다.
데이터가 아래와 같은 테이블 형태로 나눠져 있다고 하자.
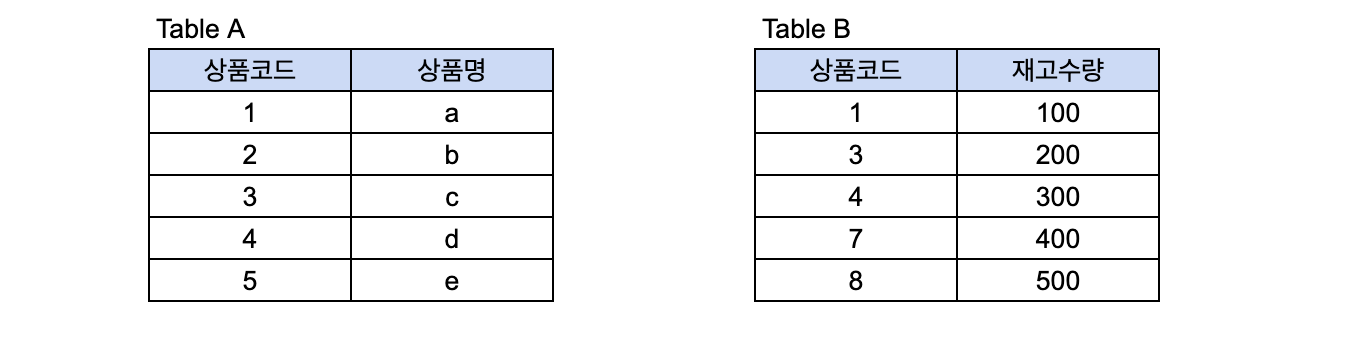
아마 같은 상품에 대해 상품명과 재고수량을 한 테이블에 놓지 않고 테이블을 나눠서 저장해놓은 모습이다.
이때, 존재하는 상품 중(재고수량이 있는) 어떤 상품(상품명)이 몇개 있는 지를 알아보고 싶다고 가정하자.
다시말해, 위 테이블 상에서 1,3,4 상품의 상품명 재고수량을 알아내고 싶다는 의미이다.
이때 Inner Join을 사용하면 된다.
1
2
3
4
SELECT A.상품코드 상품코드, A.상품명 상품명, B.재고수량 재고수량 --조회할 컬럼
FROM TableA as A -- 결합할 테이블 명. as 이후는 별칭
INNER JOIN TableB as B -- 결합할 테이블 명. as 이후는 별칭
ON A.상품코드 = B.상품코드 -- 결합 조건
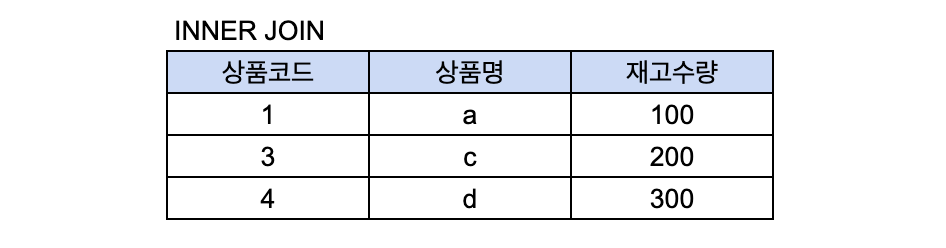
위와 같은 쿼리문을 통해, A와 B 테이블을 조인해서 아래와 같이 하나의 테이블을 만들어 데이터를 뽑아내면 되는 것이다.
Outer Join
다음으로 Outer Join에 대해 알아보자.
내가 생각하기에 Inner와 Outer Join의 가장 큰 차이점은 Inner Join은 공통된 컬럼을 기준으로 테이블을 묶기 때문에 순서가 상관이 없었지만, Outer Join에서는 순서가 중요하는 것이다. 어떤 테이블을 먼저 접근하냐 (드라이빙 테이블)에 따라 쿼리 성능에 영향을 미치므로 더 적은 데이터를 추출하는 테이블을 드라이빙 테이블로 삼는 것이 좋다.
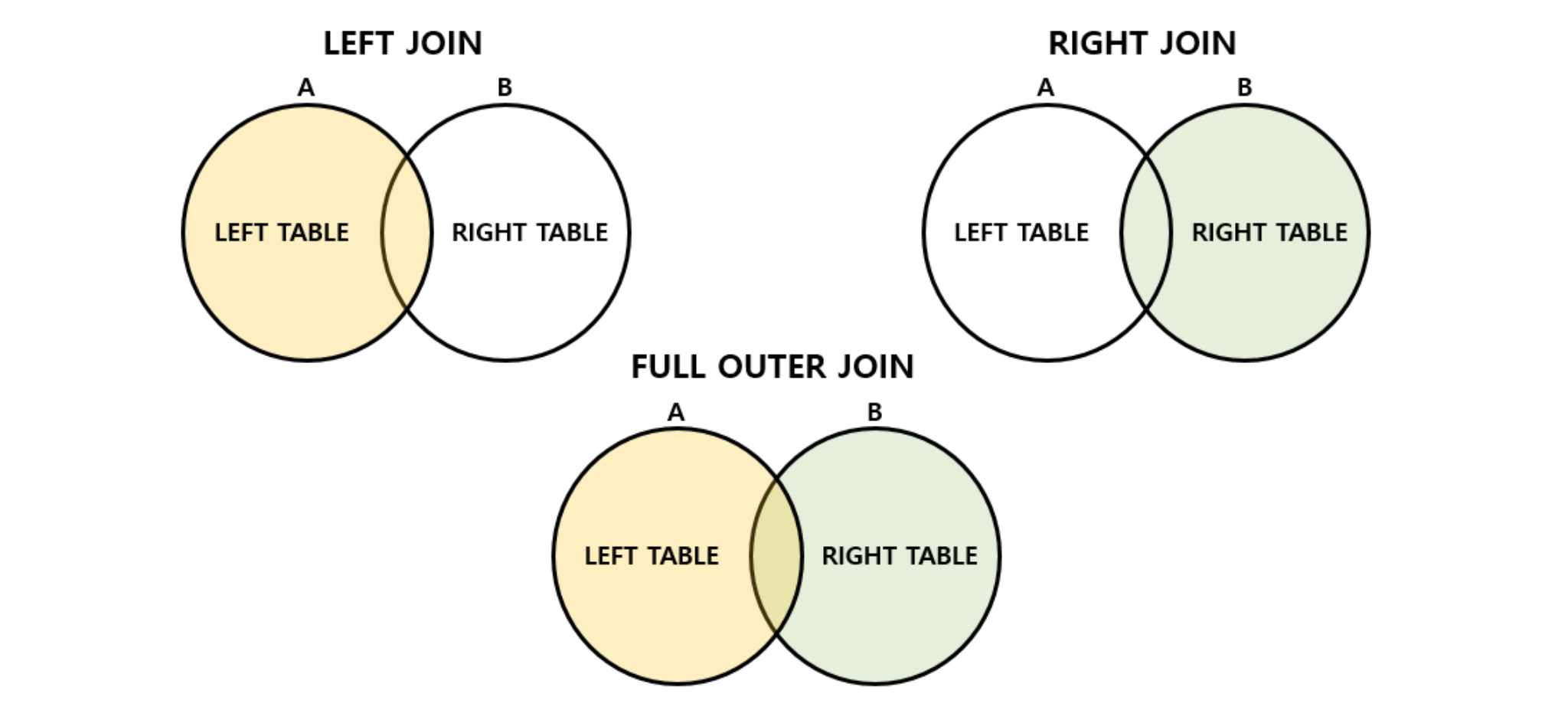
그래서 Outer Join은 Left,Right,Full Join으로 나뉠 수 밖에 없고 이 3가지 케이스들(디테일하게는 6개)를 알아보며 Outer Join 사용법에 대해 알아보자.
Left Outer Join
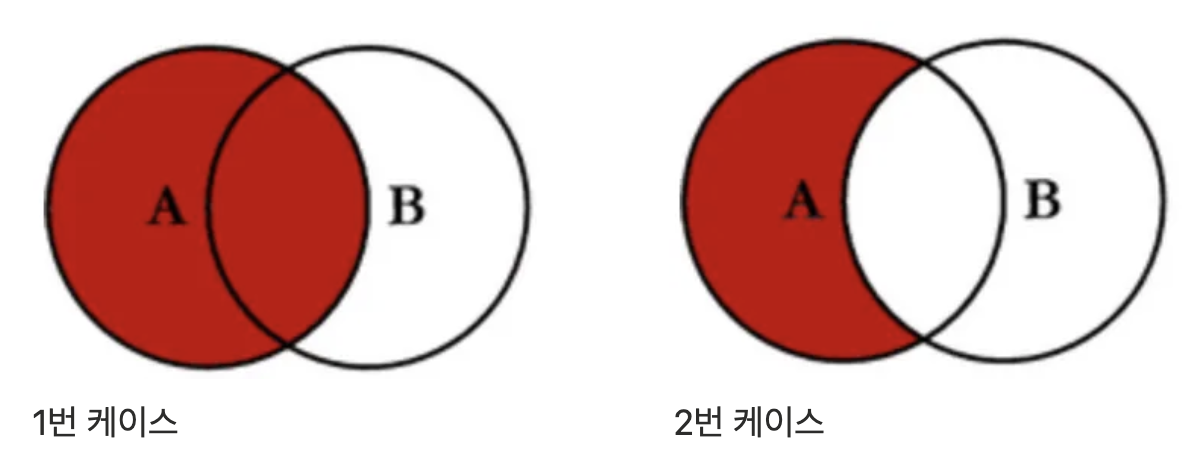
Left Join(Left Outer Join)은 왼쪽 테이블을 기준으로 조인을 하는 것이다. 다이어그램을 통해서 알아보면 위와 같은 Case들이 되는 것이다.
1번 케이스
1번 케이스처럼 데이터를 조회하기 위해 SQL을 짜고 결과가 어떻게 되는 지 알아보자
1
2
3
4
SELECT A.상품코드 상품코드, A.상품명 상품명, B.재고수량 재고수량
FROM TableA as A
LEFT OUTER JOIN TableB as B
ON A.상품코드 = B.상품코드
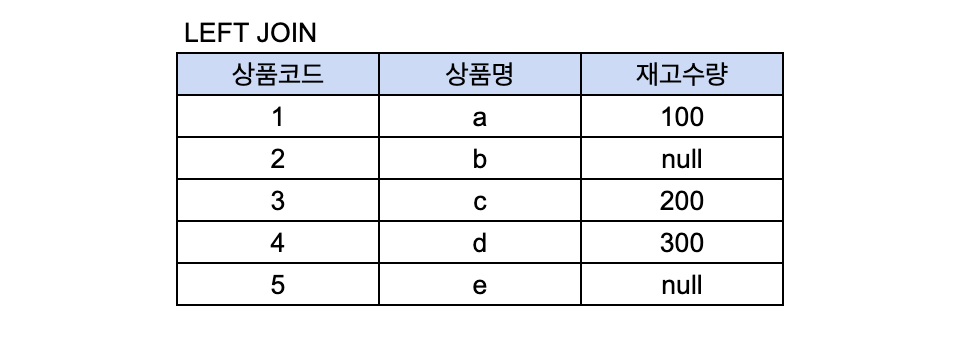
요렇게 Left Outer Join을 하면 B table에서 상품코드 2, 5에 대한 데이터가 없었기 때문에, 해당 튜플들의 컬럼들은 null값이 들어간 상태로 데이터가 조회되게 된다.
2번 케이스
그런데 1번 케이스에서 A에 속하는 모든 데이터를 조회했다. 그런데 A에만 있고, B에는 없는 데이터만 조회하고 싶을 수 있다. 예를 들어, 위 케이스에서 B 테이블에 특정 상품코드에 대한 데이터가 없다(2,5번 상품)는 얘기는 해당 상품이 아직 안 들어왔다는 것이기 때문에 이런 데이터들만 모아서 조회하고 싶을 수 있기 때문이다.
그래서 이를 빼고 조회하고 싶을 수 있고 이럴 땐 Where절로 B의 상품코드가 null인 애들만 조회하면 된다.
1
2
3
4
5
SELECT A.상품코드 상품코드, A.상품명 상품명, B.재고수량 재고수량
FROM TableA as A
LEFT OUTER JOIN TableB as B
ON A.상품코드 = B.상품코드
WHERE B.상품코드 IS NULL
Right Outer Join
Right Outer Join은 B table을 기준으로 조회를 하겠다는건데, 결국엔 Left Outer Join하고 똑같다. 그냥 테이블 순서만 바꿔서 써주면 그게 그거기 때문에 굳이 설명은 안하고 넘어가겠다.
Nested Loop Join(중첩 루프 조인)
SQL Server는 세 가지 물리적 조인 연산자를 지원한다.
- 중첩 루프 조인
- 병합 조인
- 해시 조인
여기서는 그 중 중첩 루프 조인(또는 줄여서 NL 조인)에 대해 설명하겠다.
기본 알고리즘
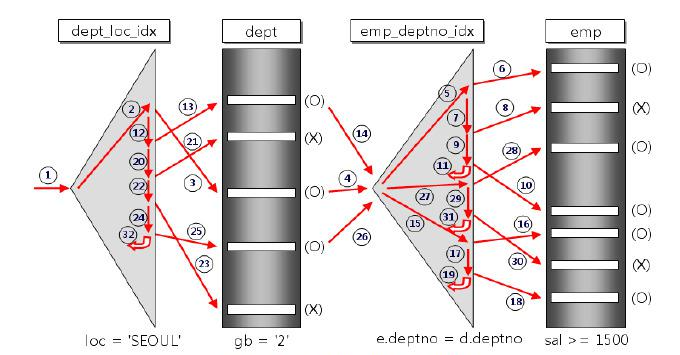
가장 단순한 형태의 중첩 루프 조인은 한 테이블(외부 테이블이라고 함)의 각 행을 다른 테이블(내부 테이블이라고 함)의 각 행과 비교하여 조인 조건을 만족하는 행을 찾습니다. (“내부 테이블”과 “외부 테이블”은 조인에 대한 입력을 나타냅니다. “내부 조인”과 “외부 조인”은 논리적 연산을 나타냅니다.)
1
2
3
4
for each row R1 in the outer table
for each row R2 in the inner table
if R1 joins with R2
return (R1, R2)
이중 루프 구조로 인해 ‘Nested Loops’라는 이름이 붙었다. 이 방법은 외부 테이블의 크기와 내부 테이블의 크기를 곱한 만큼의 비교를 수행하므로, 입력 테이블의 크기가 커질수록 비용이 급격히 증가한다. 따라서, 내부 테이블에 적절한 인덱스를 생성하여 비교해야 할 행의 수를 줄이는 것이 성능 향상에 도움이 된다.
예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
CREATE TABLE Customers (
Cust_Id INT,
Cust_Name VARCHAR(10)
);
INSERT INTO Customers VALUES (1, 'Craig');
INSERT INTO Customers VALUES (2, 'John Doe');
INSERT INTO Customers VALUES (3, 'Jane Doe');
CREATE TABLE Sales (
Cust_Id INT,
Item VARCHAR(10)
);
INSERT INTO Sales VALUES (2, 'Camera');
INSERT INTO Sales VALUES (3, 'Computer');
INSERT INTO Sales VALUES (3, 'Monitor');
INSERT INTO Sales VALUES (4, 'Printer');
1
2
3
4
SELECT *
FROM Sales S
INNER JOIN Customers C ON S.Cust_Id = C.Cust_Id
OPTION (LOOP JOIN);

위 쿼리는 Sales 테이블과 Customers 테이블을 Cust_Id를 기준으로 내부 조인하며, LOOP JOIN 힌트를 사용하여 옵티마이저가 Nested Loops Join을 사용하도록 강제한다.
주요 용어 정리
Nested Loop Join에서는 다음과 같은 주요 용어들이 사용되니 미리 알아보자
- Driving Table(외부 테이블, Outer Table): 조인을 할 때 먼저 액세스되어 주도하는 테이블
- Driven Table(내부 테이블, Inner Table): 나중에 액세스되는 테이블
여기서 Driving Table은 옵티마이저가 결정하고 자연스레 Driving Table이 아닌 테이블은 Driven Table로 결정된다.
ex) 학생 테이블과 학교 테이블로 예를 들면 이름이 홍길동인 학생의 학교 정보를 알고 싶다면 학생 테이블이 Driving Table이 되는 것이고 서울대학교의 학생들의 정보를 보고 싶다면 학교 테이블이 Driving Table이 되는 것이다.
Nested loop join 특징
1. 메모리 사용량이 적다
메모리에 한 번에 많은 데이터를 올리지 않고 개개의 로우에 대해서 실행되므로 메모리의 사용량이 많지 않습니다.
2. 바깥 테이블과 안쪽 테이블 결정을 어떻게 하냐에 따라 성능차이가 발생한다.
Driven Table이 크면 클수록 매번 많은 row를 탐색하게 되어 성능이 떨어진다.
→ 따라서 작은 테이블을 driving table로 삼고, 인덱스가 잘 걸린 테이블을 driven으로 쓰는 게 좋다.
Ex)
작은 테이블을 driving table로 사용하는 경우
- Customers: 3건 → 바깥 루프
- Sales: 100만 건 → 인덱스 활용해서 빠르게 탐색
→ 매우 효율적. 3건만 인덱스 탐색.
큰 테이블을 driving table로 사용하는 경우
- Sales: 100만 건 → 바깥 루프
- Customers: 3건 → 인덱스 없음 시 테이블 전체 탐색
→ 매우 비효율적. 100만 건 * 3건 = 최대 300만 비교.
3. Outer 테이블의 조인 컬럼 인덱스 유무가 매우 중요하다.
인덱스가 존재하지 않으면 Outer 테이블에서 읽히는 건마다 Inner 테이블 전체를 스캔하기 때문이다.
이 때 옵티마이져는 Sort Merge Join이나 Hash Join을 고려한다
OLTP 시스템에서 조인을 튜닝할 때에는 일차적으로 NL Join 부터 고려하는 것이 올바른 순서다.
우선 NL Join 메커니즘을 따라 각 단계의 수행 일량을 분석해 과도한 Random 액세스가 발생하는 지점을 파악한다. 조인 순서를 변경해 Random 액세스 발생량을 줄일 수 있는 경우가 있지만, 그렇지 못할 때는 인덱스 컬럼 구성을 변경하거나 다른 인덱스의 사용을 고려해야 한다.
여러가지 방안을 검토한 결과 NL Join이 효과적이지 못하다고 판단될 때 Hash Join이나 Sort Merge Join을 검토한다
4. 부분범위처리를 하는 경우에 유리해진다
다른 방식의 조인들은 원천적으로 부분범위 처리가 불가능하기에
부분범위처리로 처리하고자 한다면, Nested Loop Join을 선택해야 한다.
5. 처리량이 적은 경우 유리하다
실행 특성상, 처리량이 적은 경우에 유리하다.
하지만, 랜덤 엑세스가 잦게 발생하므로(매 ROW 당 랜덤엑세스)
데이터량이 많다면 큰 부담이 될 수 있다.
NESTED LOOP JOIN의 성능 개선 포인트
적절한 드라이빙 테이블의 선정
아까도 말했짐나 드라이빙 테이블을 어떻게 선정하냐에 따라 성능차이가 많이 발생할 수 있다. 그래서 적절하게 드라이빙 테이블을 선정해야하고 이때 우리가 원하는 드라이빙 테이블을 유도하는 두가지 방법이 있다.
드라이빙 테이블 유도 방법
1. 힌트의 사용
1
2
/*+ORDERED*/-- FROM절에 기술한 테이블 순서대로 제어
/*+LEADING (table명)*/-- 힌트 내에 제시된 테이블이 드라이빙으로 처리됨
가장 쉬운 방법은 위와 같이 힌트를 사용하는 방법입니다. 위의 두가지 힌트 중 하나를 사용하시면 됩니다. 만약 위의 두가지 힌트를 동시에 사용하게 되면 LEADING 힌트는 적용되지 않습니다.
2. 뷰를 사용한다.
뷰를 통해서 데이터를 먼저 읽어낼 수 있고 뷰로 데이터를 읽은 결과로 다음 테이블로 연결을 시도한다면 조인 순서를 제어할 수 있습니다.
결론
Database Join은 관계형 데이터베이스에서 매우 중요한 개념이다.
- Inner Join: 교집합을 구하는 조인으로, 가장 일반적으로 사용
- Outer Join: 한쪽 테이블을 기준으로 조인하여 NULL 값도 포함
- Nested Loop Join: 작은 테이블을 드라이빙 테이블로 사용할 때 효율적
성능 최적화를 위해서는 적절한 드라이빙 테이블 선정과 인덱스 활용이 중요하다. 특히 Nested Loop Join에서는 작은 테이블을 드라이빙 테이블로 사용하고, 조인 컬럼에 인덱스를 생성하는 것이 핵심이다.